8.1. Python samenvatting#
Om de data van je experiment te verwerken, analyseren en visualiseren gebruiken we Python. Python is een gratis, open-source en makkelijk te leren programmeertaal. Het wordt daarom vaak gebruikt op universiteiten. Binnen het natuurkundig practicum maken we gebruik van het platform Vocareum. In het filmpje zie je hoe je bij Vocareum komt en enkele basis functionaliteiten van Vocareum.
8.1.1. Jupyter Notebook#
In dit vak gebruiken we Jupyter Notebooks om met Python te werken. Jupyter Notebooks zijn bestanden die zowel code als tekst en afbeeldingen kunnen bevatten. Ze kunnen dus door mensen gelezen worden en de computer opdrachten geven. Wanneer je Python (bijvoorbeeld in een Jupyter Notebook) opstart, wordt er een kernel gemaakt. Een kernel is de tolk tussen jouw code en “de computer”. Een kernel kan ook dingen voor je onthouden, zoals variabelen. Hierbij moet je wel opletten met de chronologie van je code, omdat Python line voor line je code uitvoert. Je kan dus niet eerst een variabele gebruiken en dan deze definiëren.
8.1.2. Libraries#
Voor Python zijn al veel verschillende modules of libraries gemaakt die we kunnen gebruiken. Deze modules bevatten kant en klare functies die je kunt gebruiken. Omdat we die modules vrijwel altijd nodig hebben, beginnen we bovenaan met deze modules te importeren:
import numpy as np #inladen van lib. voor div. berekeningen
import matplotlib.pyplot as plt #inladen van lib. voor plotten
from scipy.optimize import curve_fit #inladen van lib. voor functiefit.
De eerste module helpt bij het maken van plots. De tweede module bevat functies voor diverse berekeningen, de laatste module zal worden
gebruikt om een trendlijn te fitten. Je hoeft een library in een Notebook maar één keer te importeren omdat de kernel het vervolgens
onthoudt. Om een functie uit een library aan te roepen, gebruik je library.functie. Omdat we hierboven bijvoorbeeld numpy een afkorting
hebben gegeven, moeten we nu np.mean gebruiken om bijvoorbeeld de mean functie in numpy aan te roepen.
Achter elk commando staat een #. Dit wordt niet geïnterpreteerd tijdens het compileren (het verwerken van codetaal naar uitvoerbare acties door de computer). Het is commentaar om je codetaal leesbaar te maken voor anderen.
8.1.3. Data opslaan en verwerken#
Je kunt je data opslaan in een array (lijst). Vervolgens kun je alle waarden in die lijst bewerken, plotten, printen etc. In het onderstaande voorbeeld noemen we de array a en printen we de waardes.
a = np.array([0.0, 1.0, 1.2, 0.8, 0.5]) #de array wordt aangemaakt
print(a) #de waarden in de array worden geprint.
[0. 1. 1.2 0.8 0.5]
Of, via live programming:
De volgende functies worden vaak gebruikt in de statistiek:
np.mean(a) #Uitrekenen van de gemiddelde waarde van a
np.std(a,ddof=1) #Uitrekenen van de standaard deviatie van a
np.std(a,ddof=1)/np.sqrt(len(a)) #Uitrekenen van de standaard fout van a
Bij het berekenen van de standaard deviatie (np.std) gebruiken we de optie ddof = 1 zodat er wordt gedeeld door \(N - 1\), in plaats van door \(N\). In de laatste regel gebruiken we len(a). Python rekent voor ons uit hoeveel elementen de array a bevat. Netter zou zijn om steeds de waarden die berekend worden op te slaan, waarbij we een duidelijke naam gebruiken:
average_a = np.mean(a) #Uitrekenen van de gemiddelde waarde van a
std_a = np.std(a,ddof=1) #Uitrekenen van de standaard deviatie van a
error_a = std_a/np.sqrt(len(a)) #Uitrekenen van de standaard fout van a
print(average_a)
print(std_a)
print(error_a)
0.7
0.4690415759823429
0.2097617696340303
8.1.4. Printing#
Om een waarde van een variabele te printen (op het scherm weer te laten geven), wordt de print functie gebruikt. Dit command kan elk datatype printen. Enkele voorbeelden van de print functie worden hier onder gegeven, meer voorbeelden zijn te vinden op: https://www.learnpython.org/en/String_Formatting
print("Hello world") #Printen van een string (tekst).
x = 3
print(x) #Printen van een waarde van een variabele.
print("The value of x is: ", x) #Printen van een string en een variabele.
Hello world
3
The value of x is: 3
8.1.5. Functies#
Vaak gebruik je een stukje code meerdere malen. Soms met andere waarden. Als dat gebeurt is het handig om zelf een functie te schrijven. Een functie moet je definiëren en krijgt een specifieke naam. Achter de functienaam specificeer je de input variabelen. De variabelen binnen in de functie worden enkel tijdelijk opgeslagen binnen in de functietemp_var en kunnen dus niet buiten de functie worden gebruikt. Dit heet een local variable.
def sum_function(i1, i2): #de somfunctie vraagt 2 input waarden
temp_var = i1 + i2 #deze waarden worden opgeteld en opgeslagen
return temp_var #de somwaarde wordt vervolgens teruggegeven.
# Hieronder wordt onze functie aangeroepen met als input variabelen 3 en 5.
# x zal de waarde aannemen die de functie terug geeft.
x = sum_function(3, 5)
print(x) # Dit print 8
8
8.1.6. Plotten#
Data lezen uit een tabel is niet handig, zeker niet met grote data sets. Daarom wordt data meestal gevisualiseerd in een plot. Plots zijn essentieel voor zowel de analyse van data - bijvoorbeeld voor het aantonen van een relatie tussen twee grootheden - als de presentatie ervan. Wanneer je een artikel of verslag schrijft over de resultaten van je onderzoek vormen plots een onmisbare ondersteuning voor je argumentatie. Ook uitkomsten van simulaties of een berekeningen kunnen overzichtelijk worden weergeven in een plot, zie bijvoorbeeld Figuur 8.1.
In Python kun je gemakkelijk plots maken met behulp van de library matplotlib. Deze libary heeft veel verschillende soorten plots. Hieronder zal een voorbeeld van enkele plots worden gegeven. Meer voorbeelden zijn te vinden op https://matplotlib.org/stable/tutorials/introductory/pyplot.html.
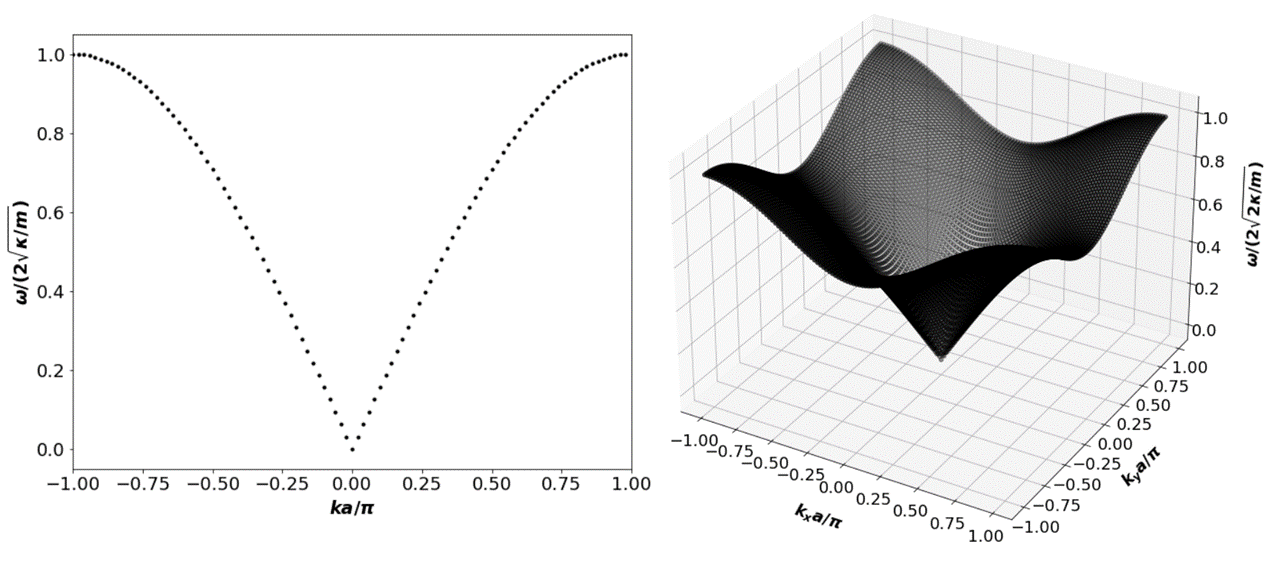
Fig. 8.1 Voorbeeld van twee simulaties gedaan in python, gevisualiseerd in een plot. De linker plot laat de dispersierelatie zien van een één-dimensionale monatomische ketting in het tight-binding model uit de vastestoffysica. De rechter plot dezelfde, maar dan voor een twee-dimensionale ketting. Programmeertalen zoals python stellen je in staat om complexe functies met een paar regels code te visualiseren, en zijn daarmee onmisbaar gereedschap voor een hedendaagse natuurkundige. Dit figuur komt uit een bachelorscriptie.#
8.1.7. Histogram#
Een histogram geeft weer hoe vaak een waarde of een bepaald bereik voorkomt in een dataset.
#Normaalverdeling in een genormaliseerde histrogram
data = np.random.normal(0,5,1000)
plt.figure(num='histfig') #Hier maken we een leeg figuur aan
plt.hist(data,bins='auto',density=1, label='Occurence') # Plot data
plt.xlabel('Values') #Label voor de x-as
plt.ylabel('Probability') #Label voor de y-as
plt.legend() #Legenda toevoegen
plt.show() #Hiermee komt het figuur op het scherm
8.1.7.1. Scatterplot#
Meetpunten uit een dataset kunnen worden weergegeven in een scatterplot. Hierbij worden enkel de punten geplot (zwart van kleur hier) en wordt er geen lijn tussen de punten getrokken. Hieronder een voorbeeld hoe een scatterplot kan worden gemaakt. Het resultaat van dit stuk code is te zien in het figuur hieronder.
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [1.1, 4.3, 9.2, 16.1, 25.1]
plt.figure(num='figscatterplot')
plt.plot(x,y,'k.', label='Measurement points')
plt.xlabel('Input voltage [V]')
plt.ylabel('Output voltage [V]')
plt.legend()
plt.show()
8.1.7.2. Errorbarplot#
Meetpunten bevatten een onzekerheid, om deze onzekerheid te visualiseren wordt gebruik gemaakt van een errorbarplot. In deze plot wordt de onzekerheid van ieder punt weer gegeven met fout vlaggen. Een voorbeeld is zichtbaar in het figuur hieronder.
x = [1, 2, 3, 4, 5]
y = [1.1, 4.3, 9.2, 16.1, 25.1]
#Onzekerheid van 0.3 en 0.1 voor x en y respectievelijk.
ux = [0.3] * len(x)
uy = [0.1] * len(x)
plt.figure(num='errorbarplot')
plt.errorbar(x, y, xerr=ux, yerr=uy, label='Measurement points.', fmt='.')
#fmt = format.
plt.xlabel('Input voltage [V]')
plt.ylabel('Output voltage [V]')
plt.legend()
plt.show()
Je zou denken dat [0.3]*len(x) als resultaat [1.5] zou hebben. Dit is echter niet het geval. Dit komt omdat het een normale array is, en geen numpy array. In dit geval wordt de array 5 keer gekopieerd, zodat het [0.3, 0.3, 0.3, 0.3, 0.3] wordt.
8.1.7.3. Curve fit#
Om een curve fit uit te voeren door een set data punten kan de curve_fit functie van het Scipy package gebruikt worden. De curve_fit functie heeft drie basis inputs: De te fitten functie, de \(x\) waardes en de \(y\) waardes. De te fitten functie is een functie met input variabelen. The \(x\) en \(y\) waarden zijn arrays met dataputen.
De curve_fit geeft twee variabelen terug: values_funcfit en covariance_funcfit. De variable values_funcfit is een array met de optimale waardes van de parameters voor de gefitte functie.
covariance_funcfit is een 2d array met de covariantie van de gefitte parameters. De waardes op de diagonaal geven de variatie van de gefitte parameters. De standaard fout van de functie met gefitte parameters kan als volgt worden berekend: np.sqrt(np.diag(covariance_funcfit)).
Raadplegen de documentatie voor extra opties: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html
from scipy.optimize import curve_fit
def exponential_function(x,a,b):
return a*np.exp(b*x)
values_funcfit, covariance_funcfit = curve_fit(exponential_function, x, y)
8.1.7.3.1. Gewogen fit#
Het is ook mogelijk om gewichten toe te kennen aan de meetpunten waardoor je een fit maakt. Dit doe je door de parameter
sigma = …, absolute_ sigma = True mee te geven, waar je op de plek van de puntjes de vector met de wegingen meegeeft.
8.1.8. Conditional Statements#
8.1.8.1. If statements#
De syntax van een if-statement is als volgt:
if conditie:
code om uit te voeren als conditie "True"is
Een paar voorbeelden van condities zijn:
a == ba < ba > ba <= ba >= ba != bTrueTrue and a == bFalse or a != b
Naast if-statements kunnen ook elif-statements en else-statements gebruikt worden. else en elif worden uitgevoerd als de voorgaande (el)if-statement False is, waarbij elif een nieuwe if-statement is.
cijfer = input('Wat is het behaald cijfer voor TN1405?')
if float(cijfer) < 5.8:
print('Je bent niet geslaagd voor dit vak')
else:
print('Je bent geslaagd voor dit vak')
8.1.9. Loops#
Loops zijn constructies die meerdere keren achter elkaar een stuk code uitvoeren. Met behulp van condities geef je aan hoe vaak de code uitgevoerd moet worden.
8.1.9.1. While loops#
De while loop is een loop die de code blijft uitvoeren zolang een conditie geldt.
while conditie:
code om uit te voeren zolang de conditie geldt
Uitgewerkt als:
a=0
while a<10:
a += 1
In de eerste regel wordt een variabele a aangemaakt. In de while loop wordt gecontroleerd of a nog steeds kleiner is dan 10. Is dit het geval dan wordt de waarde van a verhoogd met 1. De loop stopt als a=10.
Soms wordt de conditie altijd voldaan, waardoor de while loop niet stopt. Hiervoor kan je break met een if-statement in de while loop zetten.
8.1.9.2. For loops#
Een for loop is een loop die voor een vast aantal keer de code uitvoerd. Dit ziet er als volgt uit:
for i in (a, b, c, ...):
code om uit te voeren
8.1.10. Arrays#
Arrays worden veel gebruikt bij het verwerken van (meet)data. Een array heeft ook een index om de positie van een element aan te geven. Het eerste element van array a wordt aangegeven met a[0] (in Python wordt vanaf 0 geteld, niet 1!), het tweede element is a[1] et cetera. Je kan ook negatieve indexen gebruiken, dan begin je bij het laatste element, a[-1]. Numpy heeft een paar handige functies om snel een array te maken.
np.zeros(shape) # array met 0'en
np.ones(shape) # array met 1'en
np.linspace(start, stop, aantal elementen) # interval gelijk verdeeld
np.arange(start, stop, stapgrootte) # interval in aantal stappen
8.1.11. Opdrachten#
Om vertrouwd te raken met Python hebben we een aantal opdrachten voor je klaar staan in Jupyter Notebooks.