7. Data analyse, Meten & Onzekerheid#
In natuurkundige experimenten probeer je verbanden of bepaalde waarden zo goed mogelijk vast te leggen. Wat zo goed mogelijk dan precies inhoudt, blijft nu nog even onduidelijk. Wat hopelijk wel meteen duidelijk is, is dat we die waarden vrijwel nooit direct vast kunnen stellen. We voeren verschillende experimenten uit om data te verzamelen waarmee we het verband kunnen bepalen en vervolgens zo goed mogelijk de verschillende parameters in dat verband vast te stellen.
Het lukt echter nooit om de exacte waarde(n) van die parameter(s) vast te stellen: bij elke nieuwe meting zullen er kleine fluctuaties zijn (zeker als je heel precies meet). In de loop der tijd hebben we onze experimenten kunnen verbeteren, en kunnen we in kortere tijd meer metingen doen. Dit zorgt er dan ook voor dat in de loop van de geschiedenis constanten, zoals de constante van Planck, steeds beter bepaald zijn en dat de waarde in de loop der jaren verschilt.
Het gevolg van het nooit precies kunnen vast stellen van een waarde is dat als je gaat werken met die waarde je eindantwoord ook nooit perfect (gedetermineerd) is. Er zal altijd een onzekerheid zijn wat de preciese waarde daadwerkelijk is. In dit hoofdstuk leer je hoe de onzekerheid in een gemeten waarde doorwerkt in het eindantwoord (de basis, significante cijfers en bijbehorende rekenregels, ken je al), en hoe je die onzekerheid zo klein mogelijk maakt.
NOTE: De woorden meetfout en meetonzekerheid lopen vaak door elkaar heen. In veel gevallen zou meetonzekerheid preciezer beschrijven wat er bedoeld wordt. Een meetfout impliceert dat je iets echt fout doet, zonder dat je daar iets aan kunt doen. De fout komt inherent voort uit het gebruik van een instrument, van het meten zelf. In dat geval zou het dus netter zijn om te praten over de onzekerheid. Alhoewel we hier heel zorgvuldig proberen het onderscheid te maken, gebeurt het in het algemeen taalgebruik dat de twee termen onbedoeld verwisseld worden.
7.1. Doel#
Een volledige data-analyse zal vaak bestaan uit de volgende drie fasen:
het bepalen van de betrouwbaarheid van individuele metingen en de dataset als een geheel;
het vinden en bepalen van het patroon in de data met daarbij de bepaling van de variabelen met hun bijbehorende onzekerheden;
een optimale data(re)presentatie om te overtuigen van fasen 1 & 2.
Het doel van dit onderdeel van het natuurkundig practicum is elk het ontwikkelen van een dieper begrip van de bovenstaande fasen en het leren toepassen van de bijbehorende technieken.
7.2. Grootheden, eenheden, dimensie-analyse en constanten#
In de natuurkunde meten we fysische grootheden. We onderscheiden vectoren (grootheden met een richting \(\vec{F}\) (N)) en scalairen (grootheden met alleen een waarde (\(m\) (kg)). De grootheid wordt schuingedrukt (\(U\)), bijbehorende eenheid rechtop (V).
Er zijn vijf veel gebruikte standaardeenheden (kg, m, s, K, C). Er is ook nog een zesde standaardeenheid die je minder vaak tegen komt (cd). Alle andere eenheden zijn afgeleid van deze standaardeenheden. De afleiding van de eenheid gebeurt op basis van de formule:
Voorbeeld: Afleiding van J/s
\(P = F\cdot v\)
[J/s] = [kg m s\(^{-2}\)] \(\cdot\) [m s\(^{-1}\)] = [kg m\(^{2}\) s\(^{-3}\)]
Op een zelfde wijze, op basis van eenheden (dimensie-analyse), kun je formules afleiden als je weet welke grootheden mogelijk een rol spelen. Bij het tweedejaarsvak Fysische Transportverschijnselen zal daar veel dieper op ingegaan worden. Wil je weten hoe je een dimensie-analyse uitvoert? Kijk dan eens dit filmpje:
Bij veel experimenten waarin je een verband bepaalt, maak je gebruik van een constante, bijvoorbeeld de constante van Planck. CODATA heeft een mooi lijstje gemaakt van die constanten met hun bijbehorende (relatieve) onzekerheid. Maak gebruik van deze referentie bij het opzoeken en gebruik van natuurkundige constanten.
Exercise 7.1
Gegeven de vergelijking \(F=k \cdot v^2\), wat is de eenheid van \(k\) uitgedrukt in de SI-eenheden (kg,m,s,C,K)?
Solution to Exercise 7.1
\(F = k \cdot v^2 \)
\([kg \frac{m}{s^2}] = [..] \cdot [\frac{m^2}{s^2}]\)
\(k → [\frac{kg}{m}]\)
7.3. Fouten en onzekerheden in fysische metingen#
Elke meting aan een fysische grootheid komt met een bepaalde onzekerheid in de meting. Dit komt alleen al doordat je met een meting hetgeen je meet beïnvloedt. In Figuur {number} en Figuur {number} zijn hier twee voorbeelden van gegeven. Het plaatsen van een spanningsmeter in een elektrisch circuit, verandert het inherent het oorspronkelijke elektrisch circuit. Het plaatsen van een drukmeter (buis van Venturi) in een vloeistofstroom, beïnvloedt de oorspronkelijke opstelling en daarmee de vloeistofstroming.
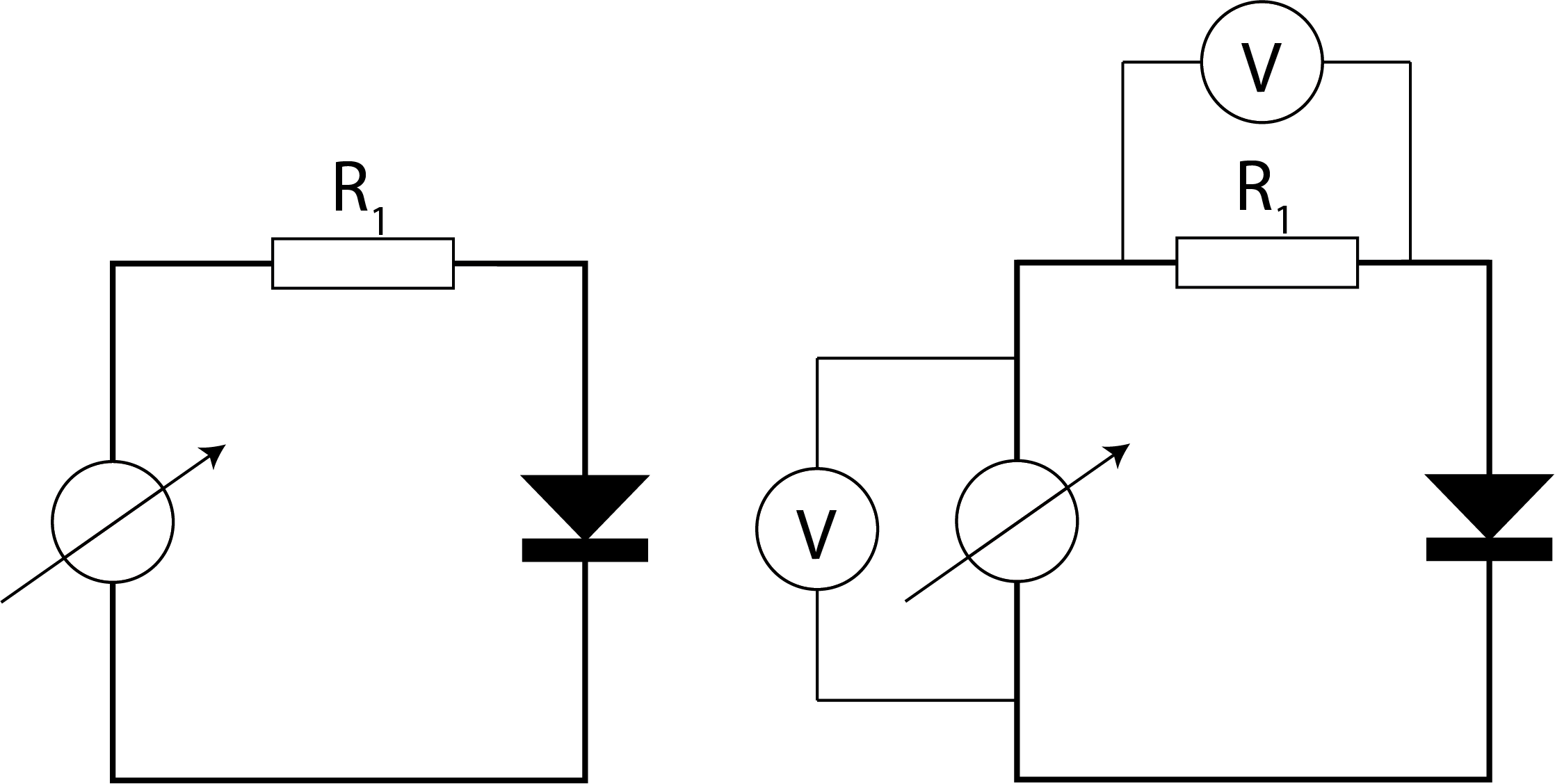
Fig. 7.1 Het meten van de spanning verandert het elektrische circuit zelf.#
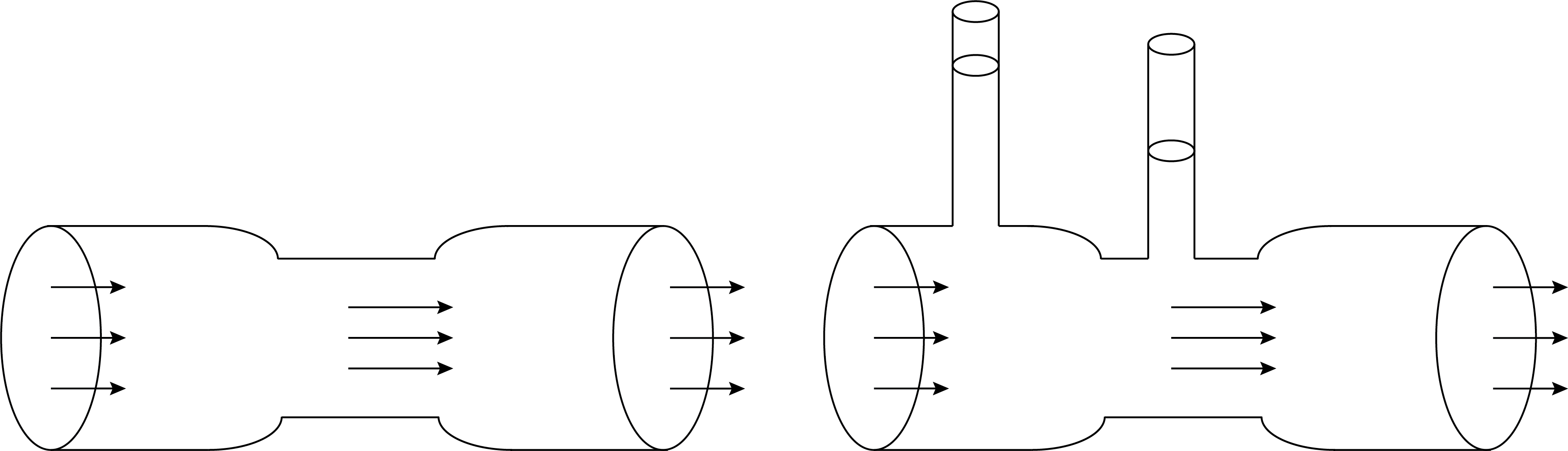
Fig. 7.2 Het plaatsen van drukmeters in een vloeistofstroom beïnvloedt de oorspronkelijke stroom.#
7.3.1. Systematische fout#
Naast beïnvloeding van de meting aan je fysische grootheid door die te meten, zijn er andere oorzaken die kunnen leiden tot ‘fouten’. We onderscheiden daarin systematische fouten van willekeurige fouten. Een systematische fout zal altijd even groot zijn, en zorgt dus voor een afwijking in je gemiddelde resultaat. Zo’n fout beïnvloedt sterk je eindresultaat. Gelukkig kun je hier wel voor corrigeren. Voorbeelden van systematische fouten zijn een nulpuntsfout en een calibratiefout, zie bijvoorbeeld Figuur {number}.

Fig. 7.3 Hier ontstaat een systematische fout wanneer je er niet op bedacht bent dat de liniaal niet bij 0 begint.#
Om er achter te komen of er een systematische fout in je data zit, kun je dit controleren met bijvoorbeeld Python. Het best valt dit uit te leggen aan de hand van een voorbeeld.
Voorbeeld: Systematische fout
Je doet een onderzoek naar de invloed van de afstand op de kracht. Je meet daartoe de afstand, maar bent bang dat er sprake is van een systematische fout in de onderlinge afstand \(r\) omdat die afstand niet goed te meten is. Als je het te verwachten verband \(F = \frac{a}{r^4}\) onderzoekt, kun je proberen de functie \(F = \frac{a}{(r+\Delta r)^4}\) te fitten. In de ideale situatie, zonder systematische fout, is \(\Delta r\) gelijk aan 0. Als dit een betere fit oplevert voor \(\Delta r \neq 0\) (Figuur {number}), dan kan \(\Delta r\) je systematische fout zijn. Natuurlijk moet je dan nog onderzoeken of deze waarde redelijk is en te verklaren valt.
In Figuur {number} is het verschil te zien tussen een fit met en zonder compensatie van systematische fout. Alhoewel de bovenste figuur een goede fit lijkt te zijn, is te zien dat de fit van de onderste figuur nog beter door alle metingen heen gaan. Straks zullen we bekijken hoe we zulke fouten systematischer kunnen onderzoeken.
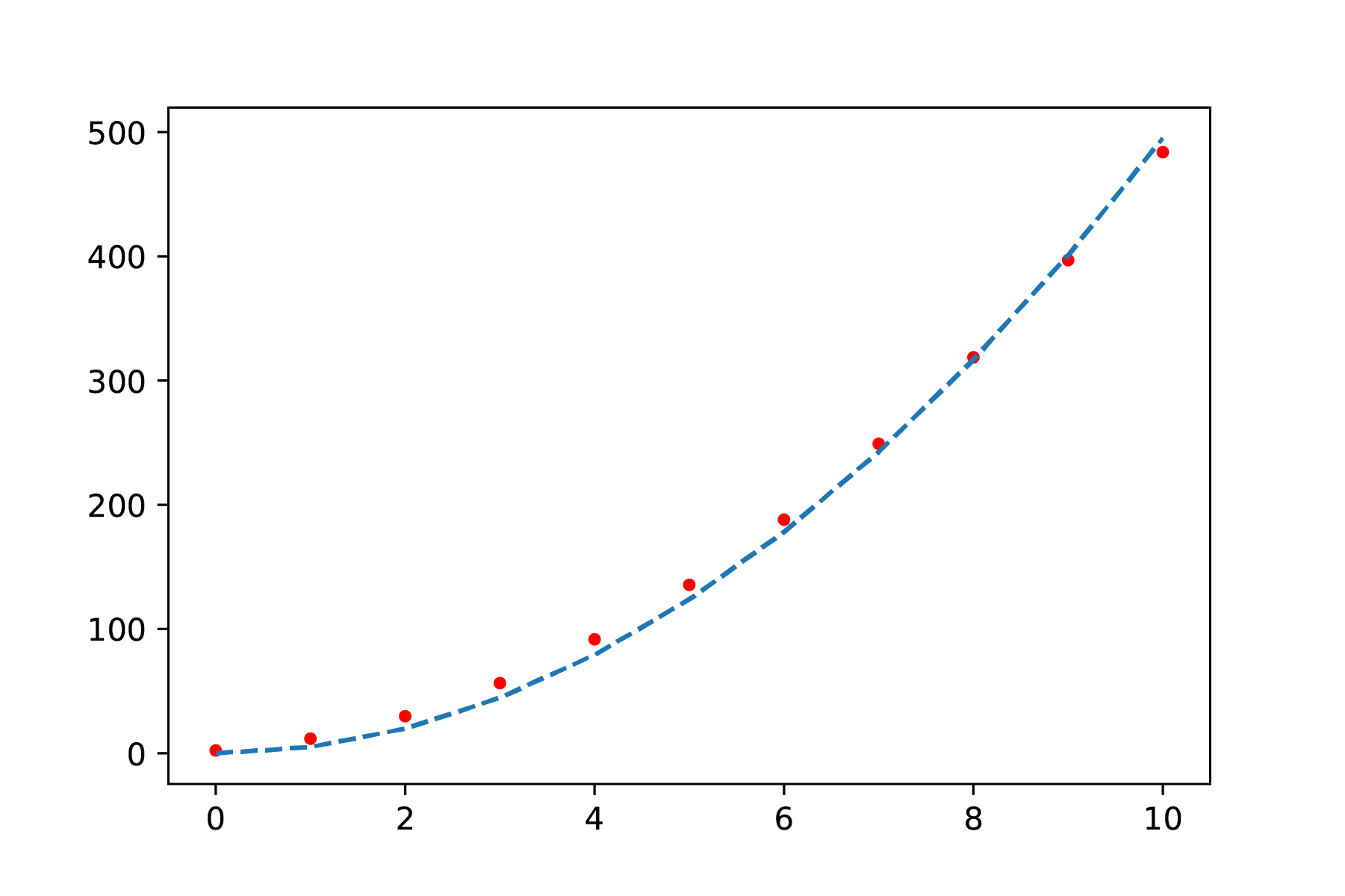
Fig. 7.4 Least-squares curve fit zonder correctie voor een systematische fout: \(F = \frac{a}{r^4}\)#
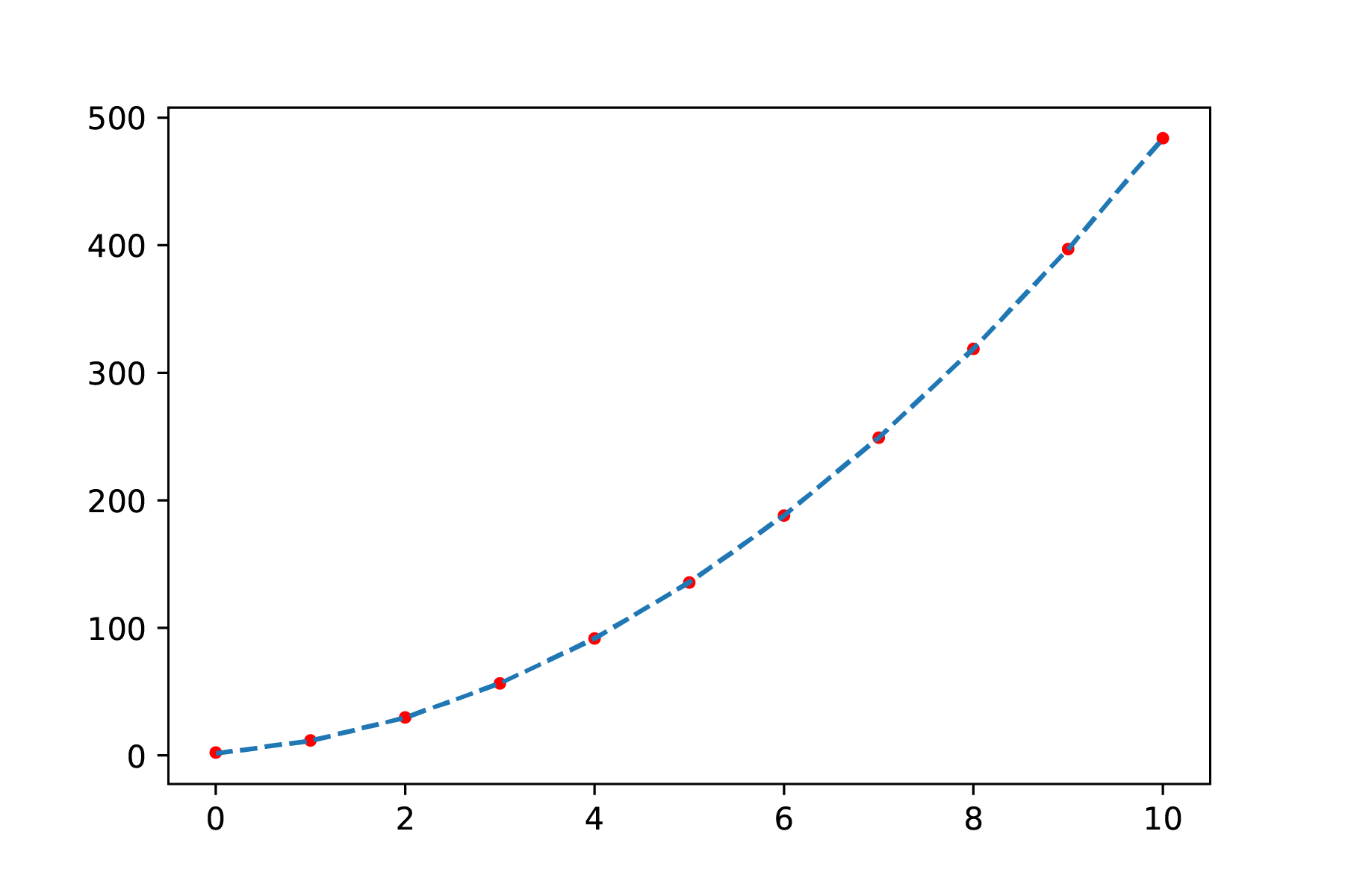
Fig. 7.5 Least-squares fit met correctie voor een systematische fout: \(F = \frac{a}{(r+\Delta r)^4}\) Duidelijk is dat de fit nu door alle meetpunten gaat.#
7.3.2. Willekeurige fout#
Een willekeurige meetfout kan ontstaan door bijvoorbeeld temperatuurschommelingen, vibraties, luchtstromingen, botsingen op moleculair niveau etc. Er is dan sprake van een technische willekeurige fout. Deze onzekerheden kun je niet altijd verkleinen. Willekeurige fouten zijn zowel positief als negatief, en middelen dus uit als je genoeg metingen doet. Je kunt er mee werken en rekenen doordat er een kansverdeling aan ten grondslag ligt. In de volgende paragrafen gaan we er van uit dat je steeds te maken hebt met een willekeurige fout, dat wil zeggen een fout die niet gecorreleerd is met andere variabelen en waarvan de kans dat die fout optreedt normaal (Gaussisch) verdeeld is.
Naast technische willekeurige fouten, kun je te maken krijgen met fundamentele fouten doordat aan sommige metingen een fysische beperking zit, bijvoorbeeld door thermische fluctuaties wanneer je meet aan stroomsterktes. Er is dan sprake van een fundamentele willekeurige fout. Deze bijdrage aan de meetonzekerheid kun je niet reduceren. De bijdrage aan de totale onzekerheid kan zowel positief als negatief zijn.
7.3.3. Instrumentele onzekerheid#
Elk instrument dat je gebruikt heeft bepaalde beperkingen. De onzekerheid kan liggen in het aflezen van het instrument, maar ook aan het instrument zelf, en dan ook nog eens aan de waarde van de gemeten grootheid. Daarnaast moet je (sommige) instrumenten eerst ijken voordat je ze gebruikt. Een fout in de ijking kan leiden tot een systematisch fout.
Bij het gebruik van instrumenten wordt vaak gebruik gemaakt van de termen precision en accuracy. Precision verwijst naar de kleine spreiding in de metingen. Precision is nauw verbonden met willekeurige fouten. Accuracy verwijst naar hoe dicht de metingen liggen op de gewenste waarde. Accuracy is nauw verbonden met systematische fouten. De vier varianten die je kunt hebben, zijn weergegeven in Figuur {number}.
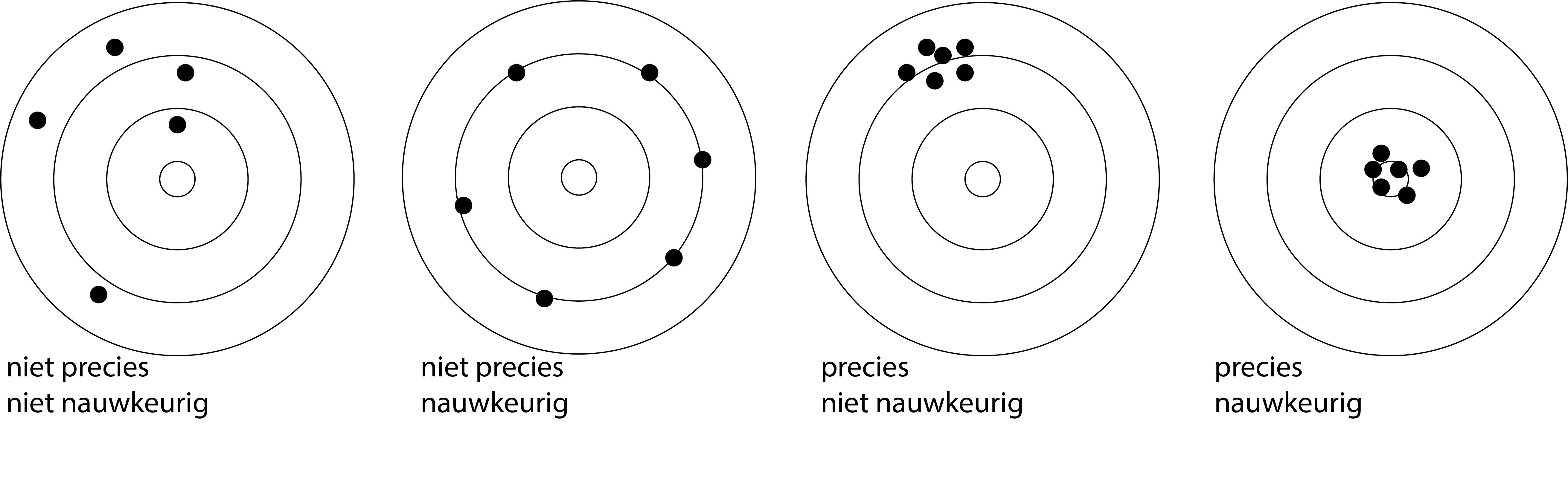
Fig. 7.6 De vier varianten aangaande nauwkeurigheid en precisie. Nauwkeurigheid is sterk gelinkt aan systematische fouten, precisie aan willekeurige fouten.#
Note
Meetschalen
De verschillende meetinstrumenten hebben verschillende meetschalen. We onderscheiden een nominale, een ordinale, een interval, een ratio en een kardinale schaal.
1. Nominale schaal
Als we alleen de kwaliteit van het object benoemen, dan heet de meetschaal nominaal. Vaststellen van de kleur van een oplossing is daarvan een voorbeeld.
2. Ordinale schaal
Als de benoeming een rangordening inhoudt, spreken we van een ordinale schaal. Een voorbeeld is het geven van cijfers voor studieprestaties. Iemand met een 10 weet meer dan iemand met een 5, maar zo iemand weet niet twee keer zoveel. Ook is het verschil in kennis tussen een 5 en een 6 meestal onvergelijkbaar met het verschil tussen een 9 en een 10.
3. Intervalschaal
Een schaal waarop gelijke verschillen wel hetzelfde betekenen maar verhoudingen niet, heet een intervalschaal. Op een intervalschaal is het nulpunt willekeurig. De celsiusschaal is daarvan een voorbeeld. 100 C is niet een twee keer zo hoge temperatuur als 50 C, maar wel is het temperatuurverschil tussen 50 C en 51 C hetzelfde als tussen 100 C en 101 C.
4. Ratioschaal
Als we behalve met verschillen ook met verhoudingen (ratio’s) van meetuitkomsten zinvol kunnen rekenen, dan vindt de meting plaats op ratioschaal. Meten van lengtes is een voorbeeld. Een tafel van 2m breed is twee keer zo breed als een tafel van 1m. We streven er naar het meten op het niveau van een ratioschaal te brengen. Een voorbeeld is het overgaan van de celsiusschaal op de absolute temperatuurschaal (de kelvinschaal).
5. Kardinale schaal
Het feit dat we op een intervalschaal met vastgelegd nulpunt of op een ratioschaal kunnen meten legt de getalwaarden niet vast. Pas als we de eenheid hebben gekozen (voor celsiustemperaturen de C, voor lengtes bijvoorbeeld de meter), kunnen we getalwaarden toekennen. We spreken dan van een kardinale schaal.
Meetonzekerheid bij analoge instrumenten
Bij analoge instrumenten moet je aflezen wat de waarde is, zie Figuur {number}. In sommige gevallen zit er achter de wijzer een spiegeltje zodat je niet al een fout maakt door de wijzer onder een hoek af te lezen. Daarnaast kun je niet oneindig precies aflezen wat de waarde is. Denk aan meetlat waar je op mm nauwkeurig kunt meten, maar afstanden tussen de mm niet goed te bepalen zijn, zeker niet wanneer de lijntjes van het liniaal dik zijn. Voor het aflezen van een analoge meter moet je een inschatting maken van de bijbehorende onzekerheid. Lees de waarde zo goed mogelijk af. Bepaal de waarden die je nog goed kunt aflezen. Neem vervolgens de helft van de waarde die je tussen twee nog te bepalen waarden als maat voor onzekerheid.
Voorbeeld: Interpoleren van afgelezen waarde
De beste aflezing van de wijzer in Figuur {number} zou 17.3 zijn. De waarde ligt duidelijk tussen 17 en 17.5, dichter bij de 17.5 dan de 17. De waarden 17 en 17.5 zou je goed kunnen aflezen. De helft van daarvan is 0.25. De onzekerheid is dan 0.3 (we mogen een onzekerheid niet naar beneden afronden).
Zoals je ziet zijn er lang niet altijd vaste voorgeschreven regels voor het bepalen van de meetonzekerheid en komt het soms neer op gezond verstand en beargumenteren hoe je aan die waarde komt.
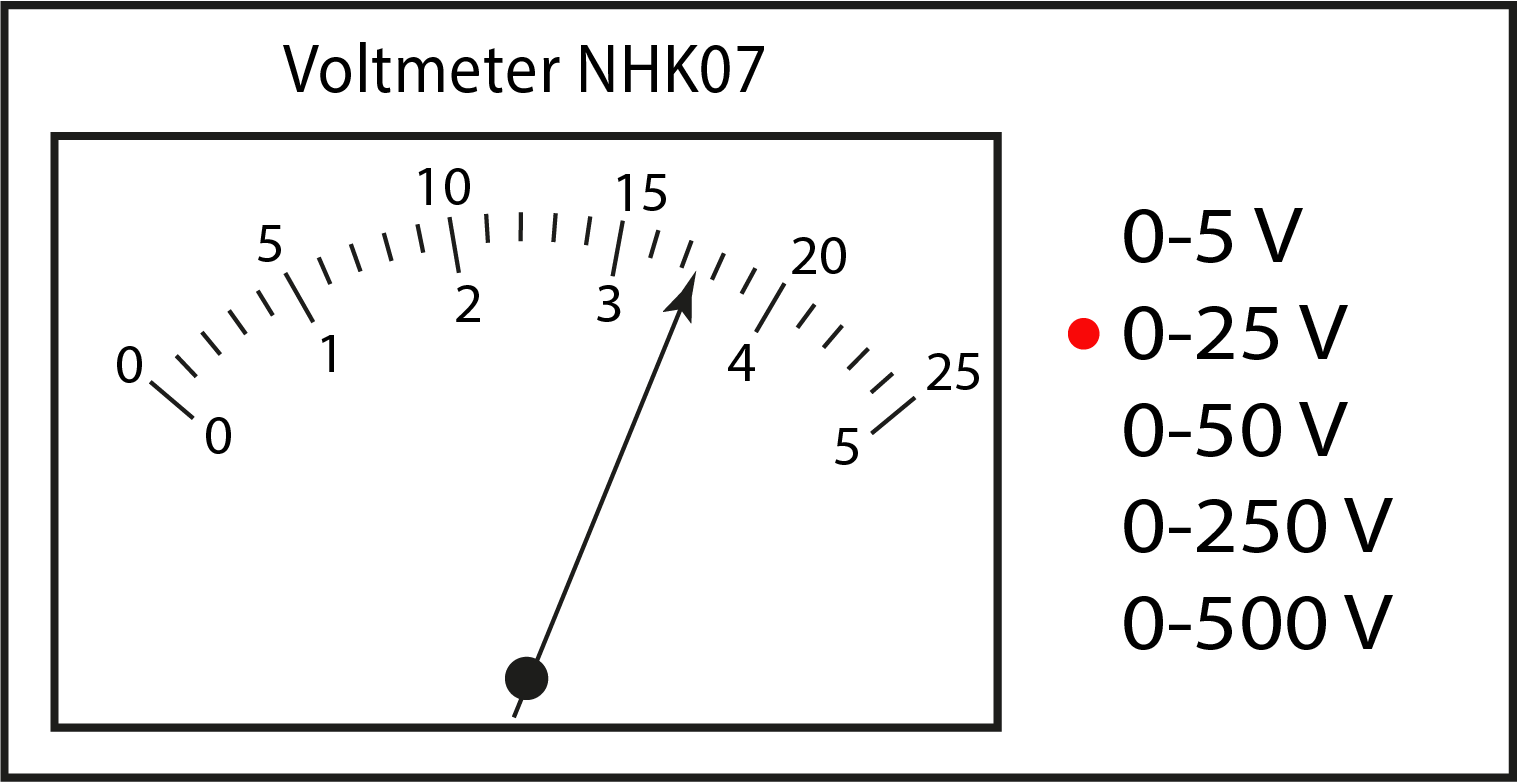
Fig. 7.7 Het aflezen van een analoge meter waarbij het eerste decimaal op basis van interpolatie geschat moet worden.#
Meetonzekerheid bij digitale instrumenten
Bij het aflezen van een digitaal instrument, zie Figuur {number} zou je zeggen dat de onzekerheid zit in het laatste decimale cijfer dat getoond wordt. Echter is de onzekerheid van digitale instrumenten veel groter dan het laatste decimale cijfer, denk maar eens aan de onzekerheid bij het gebruik van een stopwatch. Bij apparaten die je op het natuurkundig practicum gebruikt, wordt die onzekerheid soms zelfs bepaald door de leeftijd van het apparaat en de tijd dat deze aanstaat (warm worden). Voor veel digitale (dure) apparaten staat in de specificaties precies vermeld hoe de meetonzekerheid berekend moet worden.

Fig. 7.8 De digitale multimeter bepaalt de ’exacte’ waarde van een 33 kΩ (5% tolerantie) weerstand#
7.4. Gemiddelde, standaard deviatie en standaard onzekerheid#
Doordat meetwaarden kunnen flucteren, geeft het gemiddelde van een serie herhaalde metingen (\(x_i\)) de best mogelijke benadering van de werkelijke waarde. De gemiddelde waarde bereken je op basis van de serie herhaalde metingen:
Uiteraard is een herhaalde meting alleen zinnig wanneer je instrument nauwkeurig genoeg is om variaties te tonen. In de serie metingen zit een mate van spreiding: De metingen verschillen van elkaar. De standaard deviatie is een maat voor die spreiding:
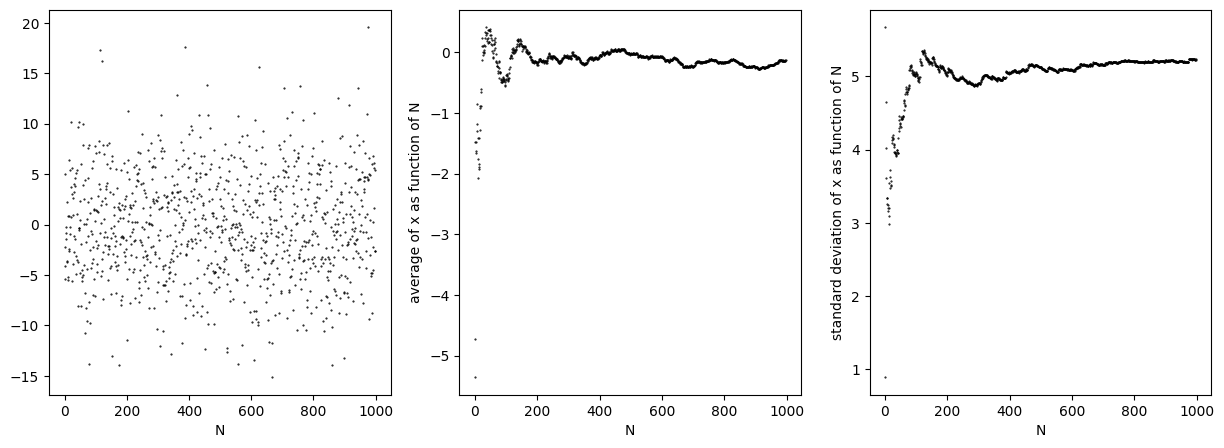
Alhoewel het gemiddelde en de standaard deviatie beter gedefinieerd worden met meer metingen, neemt de standaard deviatie niet af in waarde, zie Figuur {number}. De spreiding zelf is dan ook geen goede maat voor de onzekerheid in je gemiddelde waarde. De onzekerheid in je gemiddelde wordt gegeven door:
Een belangrijk inzicht is dat de meetonzekerheid afneemt met de wortel van het aantal metingen. Om de meetonzekerheid op basis van meerdere metingen 10x zo klein te krijgen, moet je 100x zoveel herhaalde metingen uitvoeren. Het optimum van het aantal herhaalde metingen hangt dan ook af van (1) de nauwkeurigheid die je wilt hebben, en (2) de tijd en geld die je hebt om die nauwkeurigheid te verkrijgen.
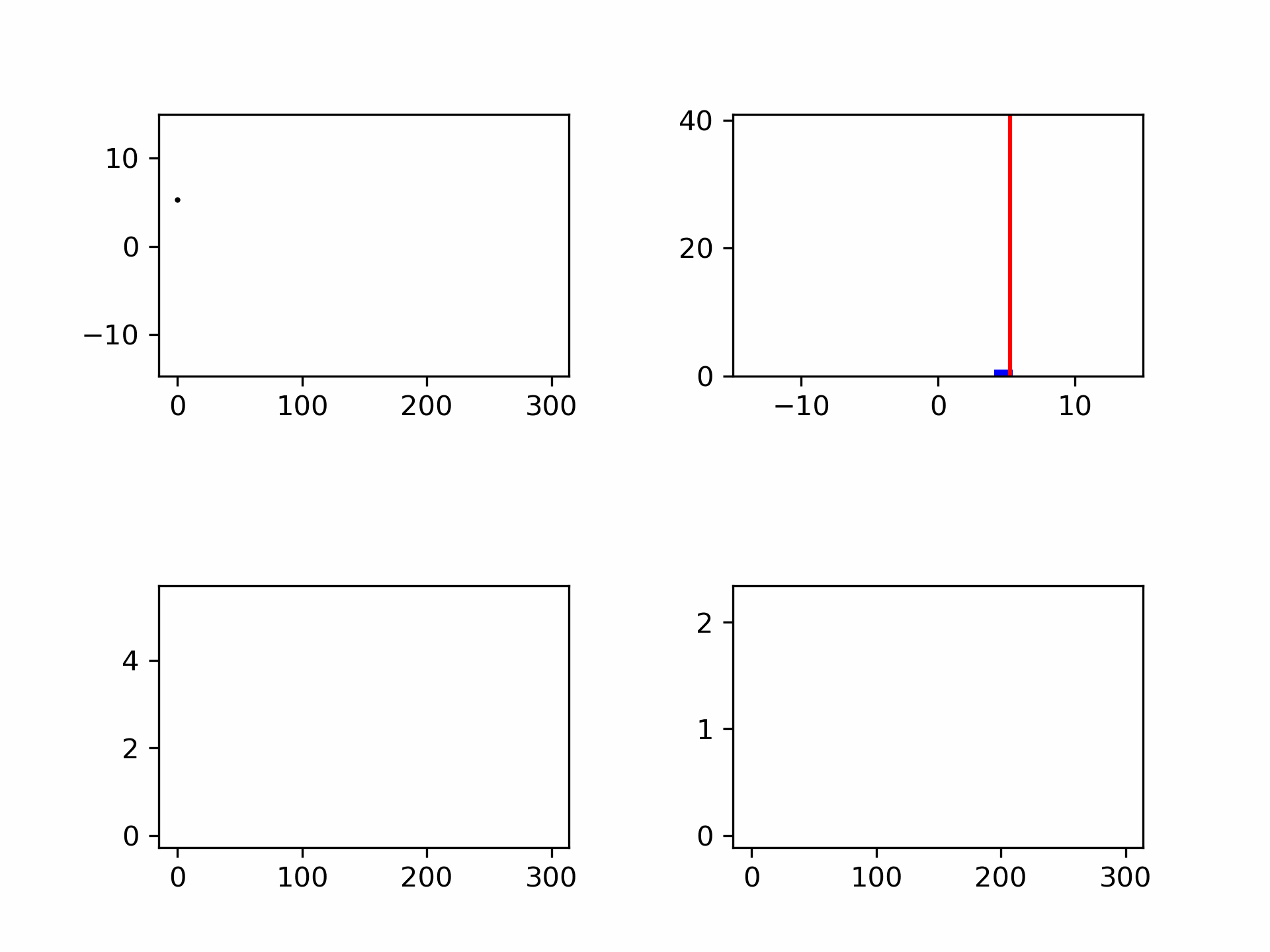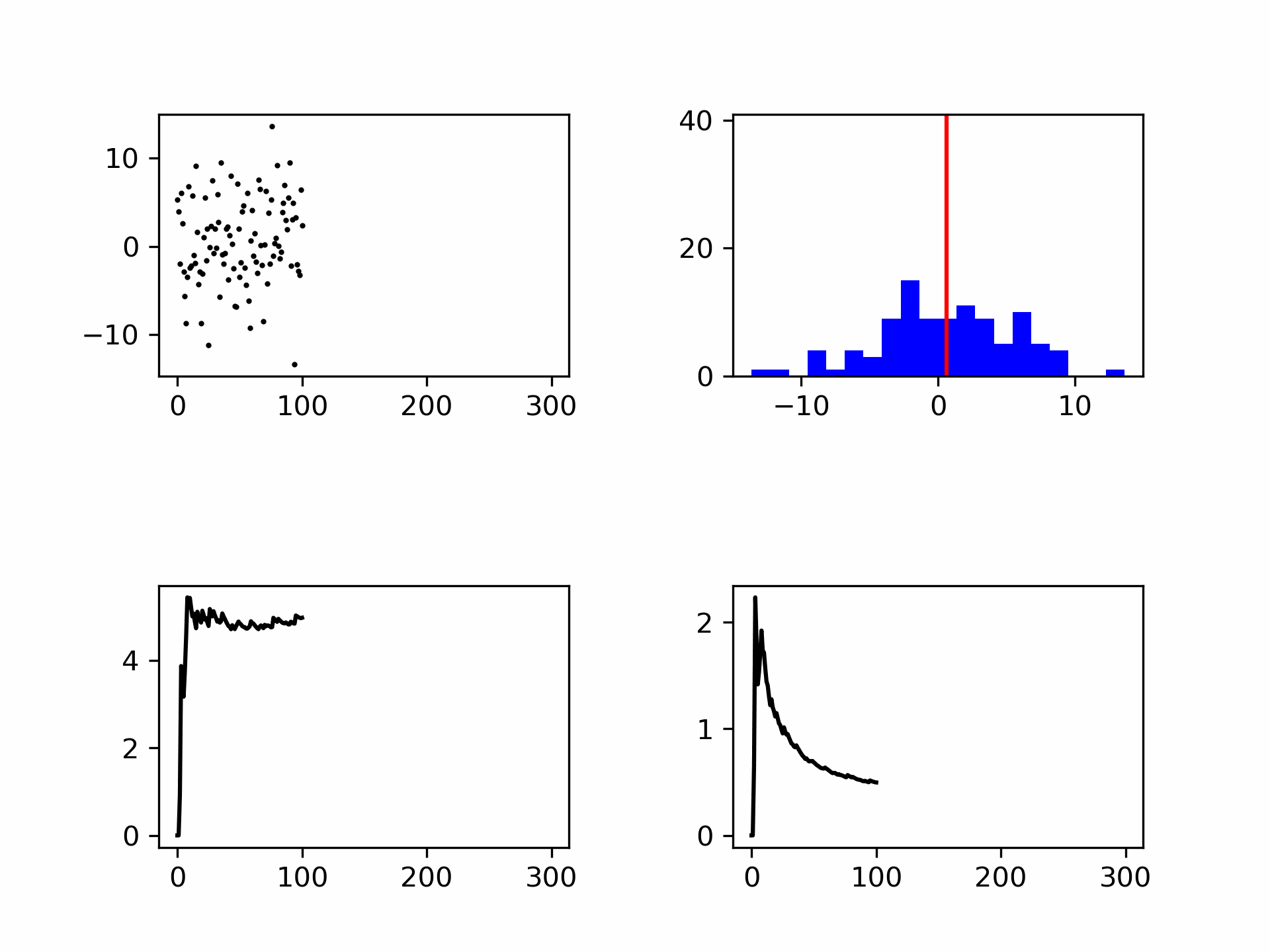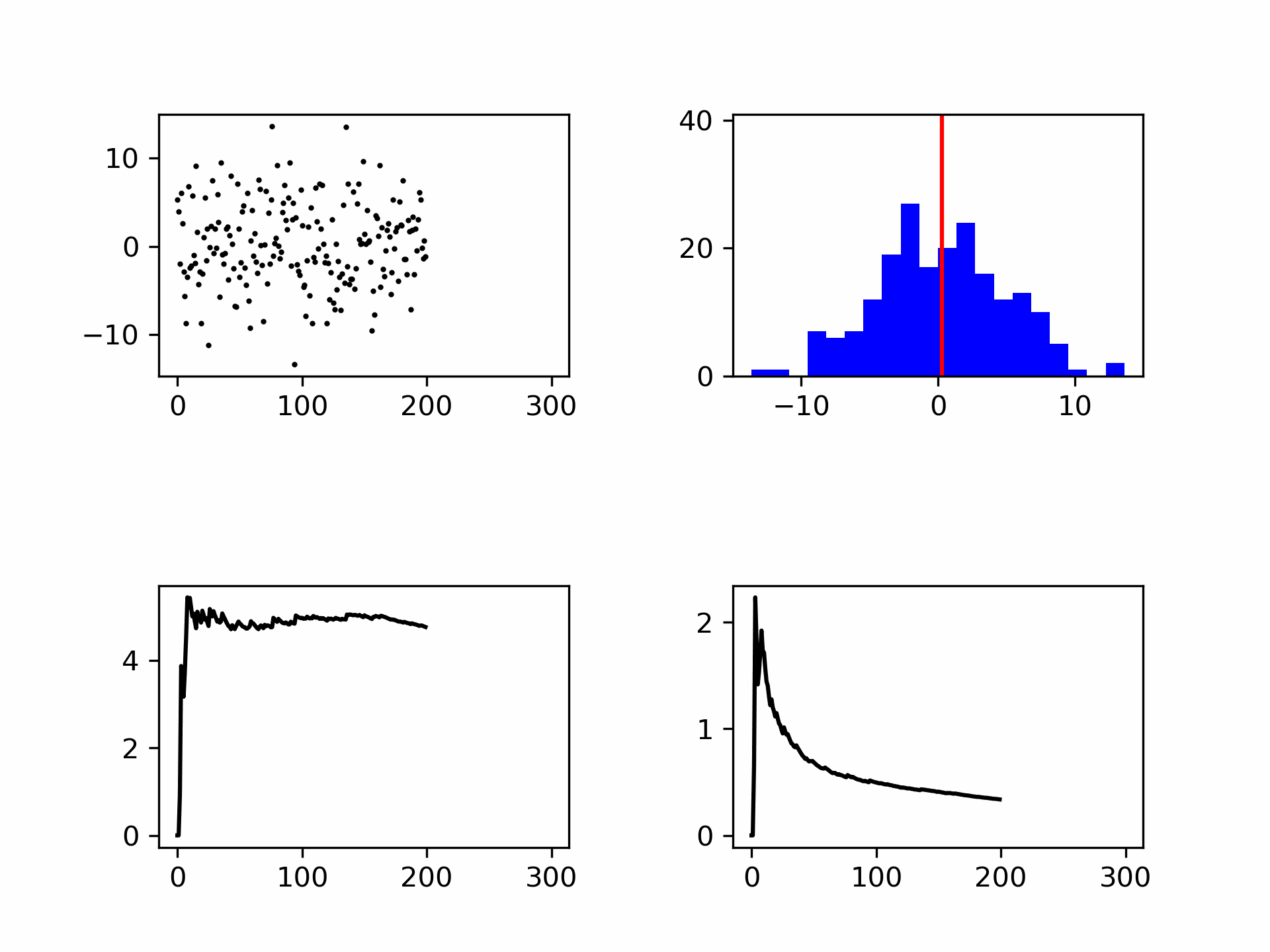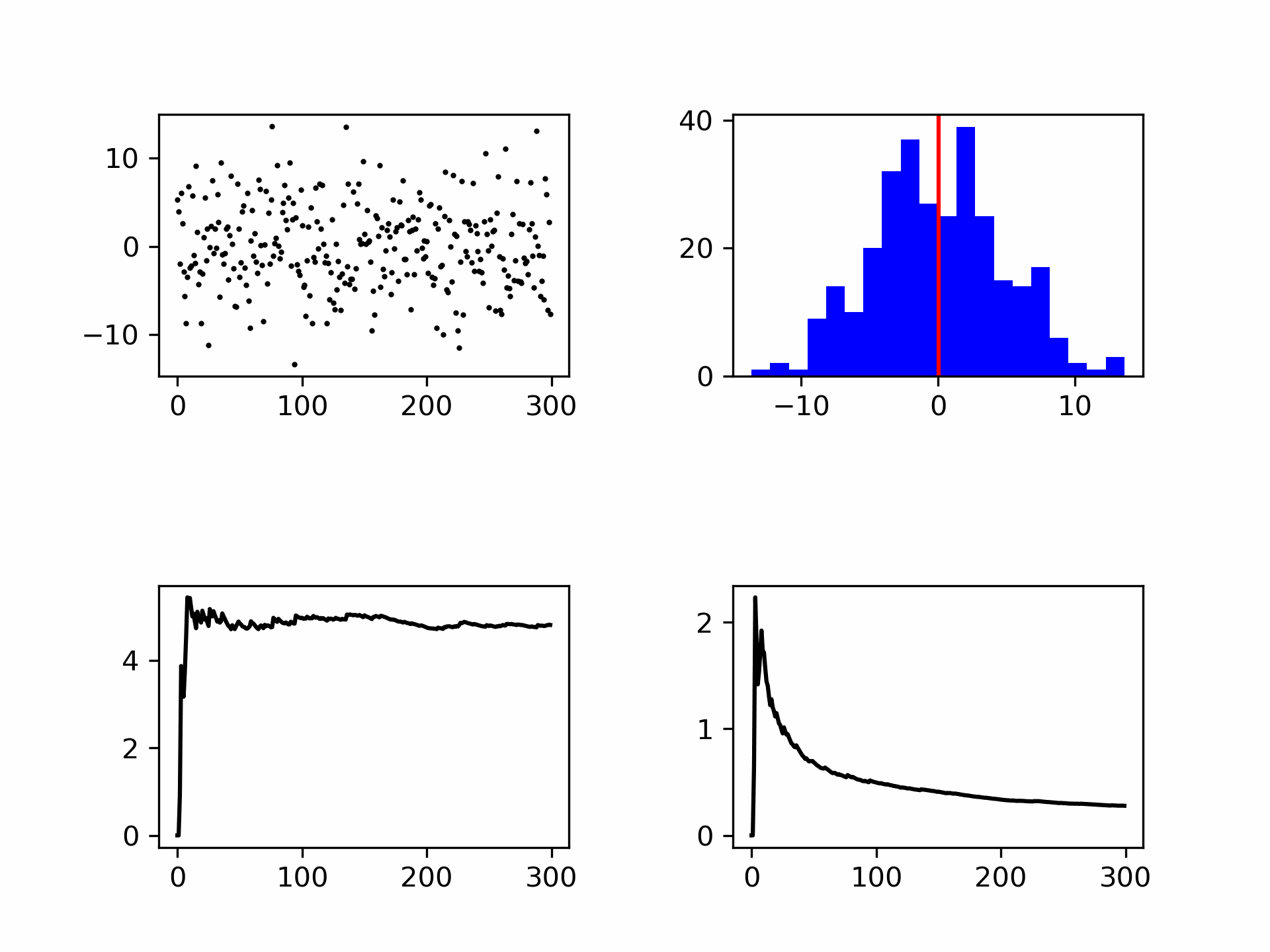
Fig. 7.9 Het genereren van ruis weergegeven als punten en in een histogram. Links onder de standaard deviatie (convergeert) en rechtsonder de meetonzekerheid (wordt kleiner met \(\frac{1}{\sqrt{N}}\)).#
De meetonzekerheid is gelijk aan de deviatie van het gemiddelde van herhaalde experimenten. Dat wil zeggen, als het volledige experiment herhaald wordt, zal er steeds een verschil zitten in het gevonden gemiddelde. De standaard deviatie daarvan is gelijk aan \(u(x)\), ofwel, er is een kans van grofweg 2/3 dat bij een herhaling van het volledige experiment het gemiddelde tussen \(\overline{x} \pm u(x)\) ligt. In onderstaande code zie je hoe je die bewering zou kunnen controleren.
Show code cell source
# we voeren hier een experiment met 1000 samples 100x uit. Als bovenstaande klopt, dan is de standaard deviatie in het gemiddelde van de verschillende experimenten gelijk aan de onzekerheid in een enkele dataset.
import numpy as np
mean_values = np.array([])
N = 100
samples = 1000
for i in range(N):
dataset = np.random.normal(1.00,0.5,samples)
mean_values = np.append(mean_values,np.mean(dataset))
print('De standaard deviatie in het gemiddelde van herhaalde experimenten is: ', np.std(mean_values,ddof=1))
print('De onzekerheid in een enkele dataset is: ', np.std(dataset,ddof=1)/np.sqrt(samples))
Show code cell output
De standaard deviatie in het gemiddelde van herhaalde experimenten is: 0.016148474312541905
De onzekerheid in een enkele dataset is: 0.015068106006343113
De uiteindelijke waarde die je gebruikt noteer je als: Meting \(\pm\) onzekerheid + eenheid. De onzekerheid bepaalt het aantal te gebruiken significante cijfers. Je gebruikt namelijk hetzelfde aantal decimale cijfers.
Voorbeeld: Notatie
Het gemiddelde van een herhaalde meting is 4.04 V met een onzekerheid van 0.1 V. De onzekerheid heeft 1 decimaal getal, de meting noteer je dan als: (4.0 \(\pm\) 0.1) V.
Exercise 7.2
Bepaal het gemiddelde, standaardafwijking en standaardfout van de volgende meetseries:
0.10; 0.15; 0.18; 0.13
25; 26; 30; 27; 19
3.05; 2.75; 3.28; 2.88
Solution to Exercise 7.2
\(\overline{x}\)=0.14, \(\sigma\) = 0.034, \(u\) = 0.02
\(\overline{x}\)=25.4, \(\sigma\) = 4.0, \(u\) = 2
\(\overline{x}\)=2.99, \(\sigma\) = .23, \(u\) = 0.1
7.4.1. Gewogen gemiddelde#
Het kan voorkomen dat niet alle herhaalde metingen even betrouwbaar zijn. Als meting 1 twee keer zo kleine onzekerheid heeft als meting 2, dan lijkt het logisch dat het gemiddelde berekend wordt door \(\frac{2 \cdot x_1 + 1 \cdot x_2}{3}\). We spreken dan over een gewogen gemiddelde. De vraag is dan natuurlijk hoe je aan de uitspraak komt over de betrouwbaarheid en hoe we daarmee aan onze weegfactor komen. Gelukkig hebben we daar net een maat voor gevonden, nl. de meetonzekerheid. De weegfactor wordt gedefinieerd door:
Het gewogen gemiddelde is daarmee:
met een bijbehorende onzekerheid van:
Merk op dat de bovenstaande formule wordt gereduceerd tot het normale gemiddelde als alle weegfactoren \(w_i\) gelijk zijn aan 1.
Exercise 7.3
In een experiment bij het natuurkundig practicum wordt de valversnelling bepaald. Dit levert de volgende waarden op bij verschillende groepjes: 9.814 ± 0.007, 9.807 ± 0.003, 9.813 ± 0.004.
Bereken het gewogen gemiddelde en de bijbehorende onzekerheid.
Solution to Exercise 7.3
9.809 ± 0.002 Merk op dat de onzekerheid in het eindantwoord kleiner is geworden!
7.5. Kansverdelingen#
Zoals aangegeven zit er spreiding in herhaalde metingen. De fysische meting \(M\) kunnen we zien als de optelsom van de fysische waarde \(G\) en ruis \(s\):
Ruis is hier ruim gedefinieerd, we verstaan er hier even alle mogelijke fouten onder. Onze interesse gaat met name uit naar willekeurige fouten. Deze zijn normaal verdeeld.
7.5.1. Normale verdeling#
Wanneer we te maken hebben met willekeurige ruis, dan kan de kans dat een waarde optreedt beschreven worden aan de hand van een normale (Gaussische) verdeling:
hierin is \(P(x)\) de kansdichtheidsfunctie, met \(\mu\) het gemiddelde waarde van de ruis en \(\sigma\) de standaard deviatie.
Een voorbeeld van een ruis signaal is weergegeven in Figuur {number} (de bijbehorende code is in een cel daaronder getoond). Het gemiddelde van deze waarden is 0. Het herhalen van metingen zorgt er dus voor dat de invloed van de ruis beperkt wordt omdat de gemiddelde bijdrage 0 is:
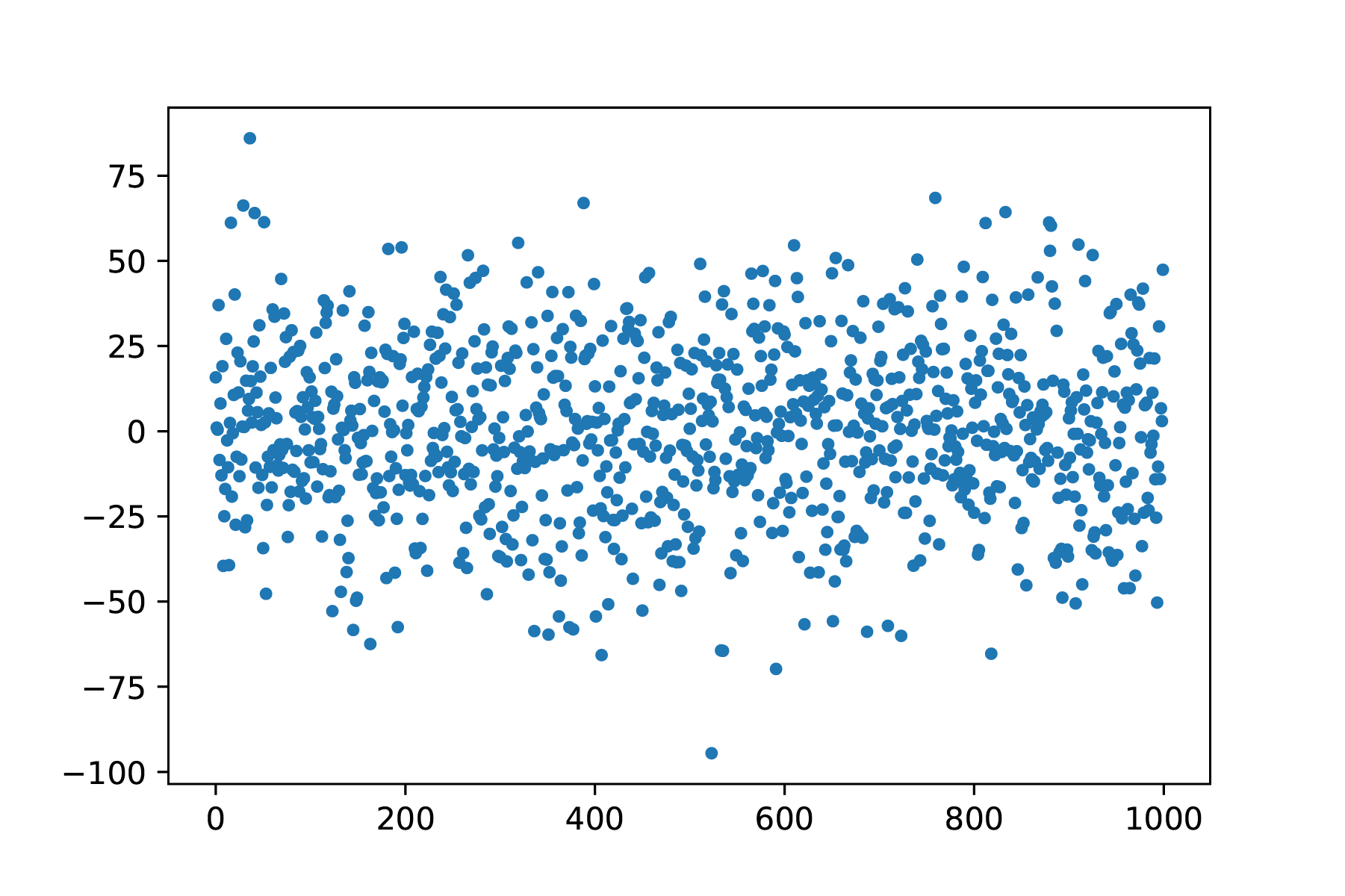
Fig. 7.10 Random noise, te zien is dat grote uitschieters voorkomen, maar minder frequent.#

Fig. 7.11 De gemiddelde waarde van ruis wordt steeds beter gedefinieerd bij herhaalde metingen.#
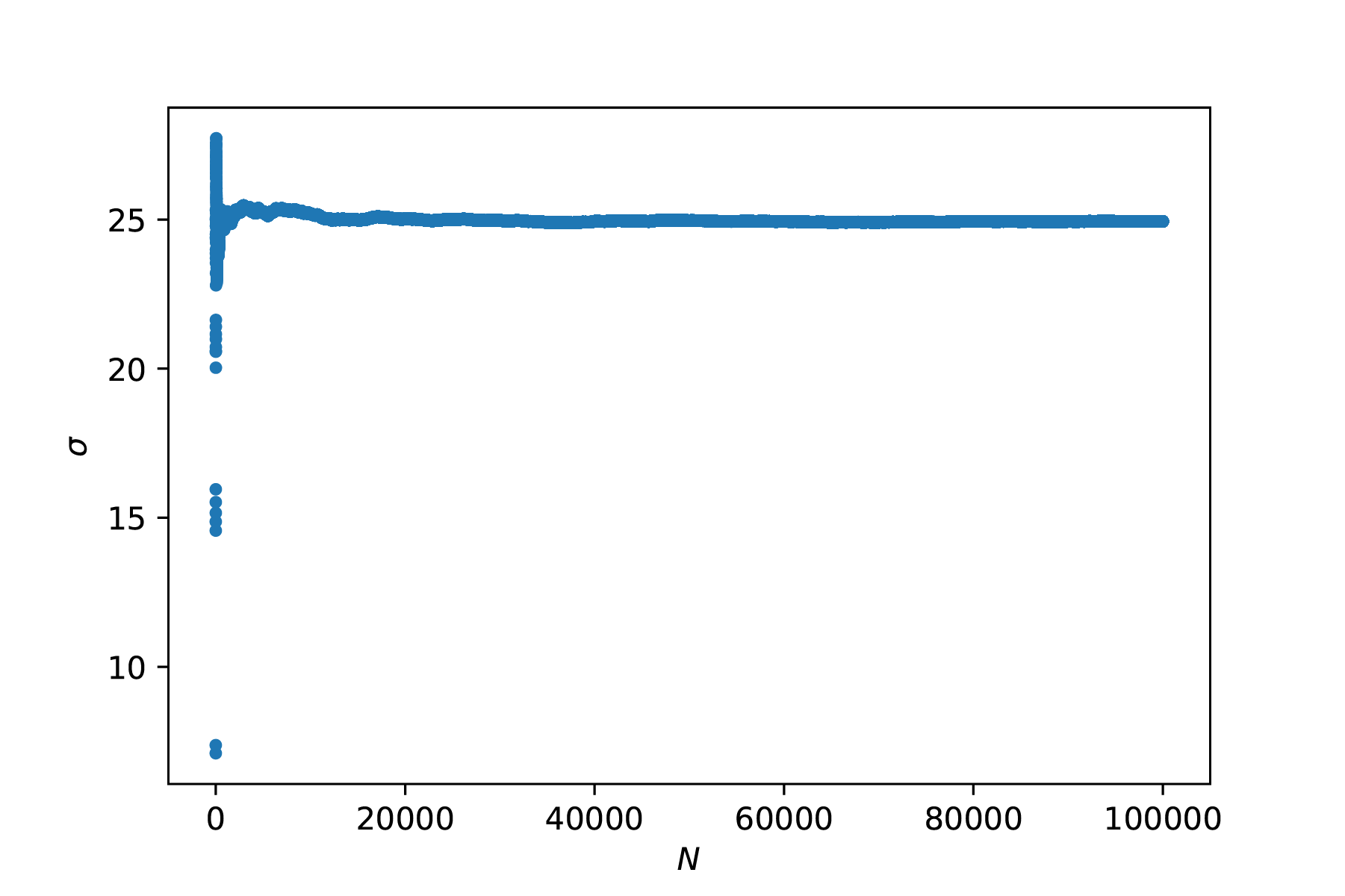
Fig. 7.12 De standaard deviatie wordt steeds beter gedefinieerd bij herhaalde metingen.#
We moeten hier wel voorzichtig mee zijn, in Figuur {number} is te zien dat een histogram van vier herhaalde metingen aan ruis steeds een net iets ander beeld geeft. Elk histogram bestaat uit een 1000 herhaalde metingen. Er is dus zelfs een onzekerheid in de onzekerheid \(\left( \frac{1}{\sqrt{2N-2}}\right )\). De precieze wijze waarop we onze waarden rapporteren is uitgewerkt in Standaard onzekerheid en significante cijfers.

Fig. 7.13 Zelfs 1000 herhaalde metingen (aan ruis) laten verschillen zien.#
Show code cell source
# Maken van 1000 random punten
x = np.random.normal(0,5,1000)
# Bereken van gemiddelde waarde en standaard deviatie
av_x = np.array([])
std_x = np.array([])
for i in range(1,len(x)-1):
av_x = np.append(av_x,np.mean(x[:i]))
std_x = np.append(std_x,np.std(x[:i],ddof=1))
# Plotten van de waarden als functie van N
fig, axs = plt.subplots(1,3,figsize=(15, 5))
axs[0].plot(x,'k.',markersize=1)
axs[0].set_xlabel('N')
axs[0].set_ylabel('')
axs[1].plot(av_x,'k.',ms=1)
axs[1].set_xlabel('N')
axs[1].set_ylabel('average of x as function of N')
axs[2].plot(std_x,'k.',ms=1)
axs[2].set_xlabel('N')
axs[2].set_ylabel('standard deviation of x as function of N')
plt.show()
/usr/local/lib/python3.11/site-packages/numpy/core/_methods.py:269: RuntimeWarning: Degrees of freedom <= 0 for slice
ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
/usr/local/lib/python3.11/site-packages/numpy/core/_methods.py:261: RuntimeWarning: invalid value encountered in scalar divide
ret = ret.dtype.type(ret / rcount)
7.5.2. Poissonverdeling#
Een tweede kansverdeling die we hier introduceren is de Poissonverdeling. De Poissonverdeling is een discrete (in tegenstelling tot de normaalverdeling) kansverdeling, die gebruikt wordt om onafhankelijke gebeurtenissen te tellen binnen een bepaalde tijd, waarbij de evenementen zelf ook op een normale verdeling zijn gebaseerd. Voorbeelden hiervan zijn radioactief verval, het aantal photonen dat op een detector valt, etc.
De kans op \(k\) gebeurtenissen binnen een bepaalde tijd met een gemiddelde van \(\lambda\) wordt gegeven door:
De standaardafwijking in een Poissonverdeling is gelijk aan de wortel van het gemiddelde (\(\sigma = \sqrt{\lambda}\)).
Voorbeeld: Poisson
In een restaurant komen dagelijks gemiddeld 20 mensen eten. Hoe ziet de kansverdeling van het aantal mensen dat komt eten er uit?
De kansverdeling van het aantal bezoekers is weergegeven in Figuur {number} De kans wordt beschreven door: \(P(X = k) = \frac{20^k e^{-20}}{k!}\).
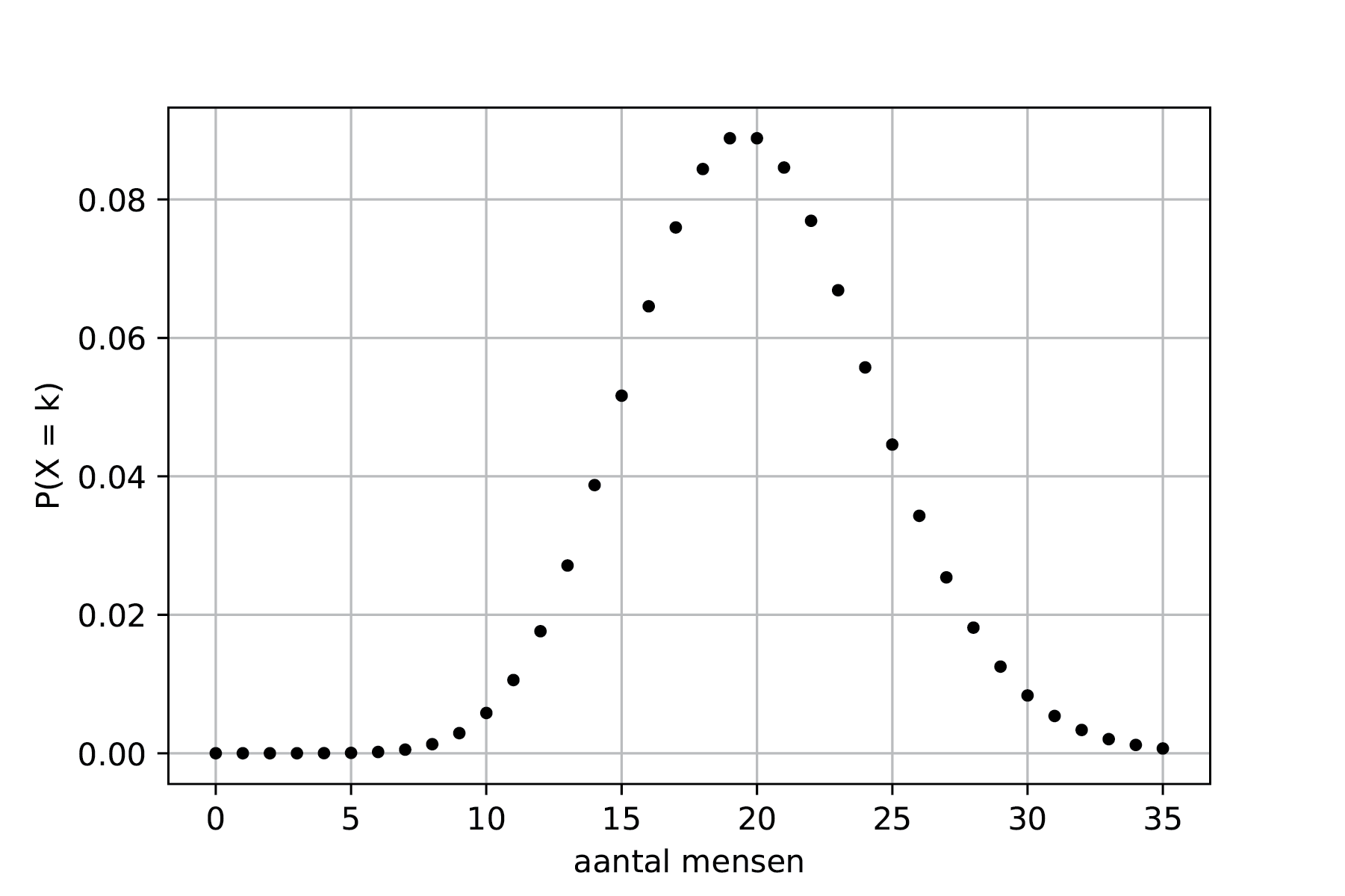
Fig. 7.14 De kansverdeling van het aantal bezoekers van het restaurant.#
Zowel de vorm als de functie lijken wat op die van de Gaussische verdeling. Maar met name bij kleine waarden voor \(\lambda\) zijn er duidelijke verschillen. Ook is het aantal events altijd groter dan 0, terwijl bij een Gaussische verdeling een verwachtingswaarde ook kleiner kan zijn dan 0.
7.5.3. Uniforme verdeling#
Als je een dobbelsteen gooit is de kans op het gooien van een 1 even groot als het gooien van een 6. Met andere woorden, de kans voor willekeurig welk getal is uniform (discreet) verdeeld. Stel nu dat we te maken hebben met een continue, uniforme kansverdeling dan geldt er voor de kansdichtheidsfunctie:
De kans dat een punt zich tussen de waarde \(X\) en \(X+dX\) bevindt (als \(X\) zich tussen \(a\) en \(b\) bevindt!), wordt dan gegeven door:
De verwachtingswaarde is eenvoudig uit te rekenen en wordt gegeven door:
en de standaard deviatie:
7.5.3.1. Monte Carlo simulatie#
Zo’n uniforme verdeling is handig bij bijvoorbeeld Monte Carlo simulaties. In zo’n simulatie wordt een groot aantal random punten aangemaakt en vervolgens wordt onderzocht waar die punten terecht komen. Voor een niet analytische oplosbare integraal kun je zo alsnog het oppervlak uitrekenen, nl:
Hierin zijn \(y_{min}\) en \(y_{max}\) de verticale grenzen die je kiest voor het maken van je random punten. Die moeten natuurlijk wel de gehele grafiek omvatten!
Een voorbeeld van een Monte Carlo simulatie is gegeven in Figuur {number} waarbij een eenvoudige integraal is uitgerekend door voor 10.000 punten uit te rekenen of geldt: \(y<x^2\). De integraal op het domein [0,5] is dan: het aantal punten dat aan deze voorwaarde voldoet gedeeld door het totaal aantal gecreeerde punten maal 5 maal 25. In zo’n Monte Carlo simulatie (wat een telprobleem is) schaalt de onzekerheid met \(\frac{1}{\sqrt{N}}\), waarin \(N\) het aantal punten is dat voldoet aan de voorwaarde (dus kies je de verticale grenzen optimaal!).
Fig. 7.15 Een voorbeeld van een Monte Carlo simulatie voor het berekenen van een integraal met behulp van een uniforme verdeling van random punten.#
7.5.4. Criterium van Chauvenet#
Herhaalde metingen leiden tot een beter gemiddelde. Echter in herhaalde metingen kunnen bepaalde waardes veel afwijken van het gemiddelde. Het kan verleidelijk zijn om een meetpunt dat wel erg veel afwijkt van de rest simpelweg af te schrijven als meetfout. Echter is dit al snel manipuleren van data en dat is niet de bedoeling. Je kunt het criterium van Chauvenet toe passen om te kijken of het meetpunt verwijderd mag worden. Het criterium van Chauvenet is een vuistregel (er zijn andere, meer gecompliceerde methoden om na te gaan of je datapunten mag verwijderen, maar die werken we hier niet uit). Het criterium van Chauvenet zegt dat een meting uit de dataset verwijderd mag worden als de kans daarop kleiner is dan \(\frac{1}{2N}\) ofwel \(P(X)<\frac{1}{2N}\).
Verder uitgewerkt houdt dit in dat je eerst het gemiddelde en de standaardafwijking uitrekent van je data, inclusief het verdachte punt. Vervolgens mag je een punt achterwege laten als het voldoet aan de volgende ongelijkheid:
waar
erf is hier de errorfunctie, de integraal van de normale verdeling. De uitkomst van deze integraal is niet algebrarisch uit te rekeken. Op https://www.danielsoper.com/statcalc/calculator.aspx?id=53 kun je de waarde voor de errorfunctie berekenen. Hieronder werken we uit hoe dat gaat in Python.
Als je het criterium van Chauvenet gebruikt om een outlier uit te sluiten, moet je dit altijd vermelden in je verslag! Daarnaast moet je wederom het gemiddelde en standaard deviatie uitrekenen na de verwijdering van het verdachte punt. Dit punt heeft immers een significant effect op je dataset
Exercise 7.4 (Outlier)
Welke meting uit de serie 1b is verdacht? Gebruik het criterium van Chauvenet om te kijken of je deze meting mag uitsluiten.
Solution to Exercise 7.4 (Outlier)
\(P_{out} = 2\cdot \text{Erf}(x = 19,\overline{x} = 25.4,\sigma = 4.0) = 2 \cdot 0.05479929\)
\(N\cdot P_{out} = 0.5479929 > 0.5\). We mogen het punt dus niet uitsluiten.
7.5.4.1. Error function(s)#
Er zijn twee soorten error functies, de \(\text{erf}(x)\) en de \(\text{Erf}(x_{out},\overline{x},\sigma)\) (ook wel de cdf functie genoemd). Die als volgt gedefinieerd zijn:
Een plot van beide is te zien in Figuur {number}
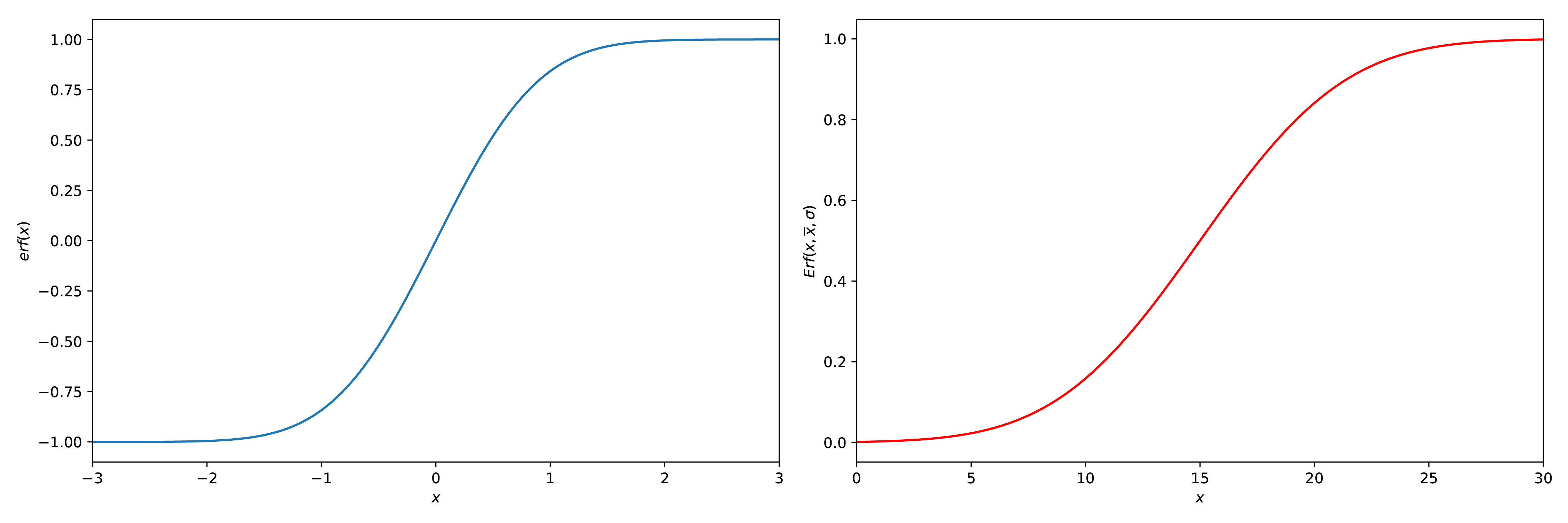
Fig. 7.16 2 plots, een met de \(\text{erf}(x)\) en een met de \(\text{Erf}(x_{out},\overline{x},\sigma)\) (rechts), \(\overline{x} = 10\) en \(\sigma = 5\).#
Beide functies zijn te vinden in de scipy.special.erf en de scipy.stats.norm.cdf functie. Wanneer je gebruik maakt van de \(\text{Erf}\) of de scipy.stats.norm.cdf functie (of de site) moet je opletten dat wanneer je een outlier naar boven gaat onderzoeken dat de functies je allemaal een waarde boven de 0.5 gaan terug geven. Dit betekent dus dat je \(P_{out\_new} = 1 - P_{out}\) moet doen. De uiteindelijke code zou dus iets in deze trant moeten zijn:
from scipy.stats import norm
#P is the dataset (a numpy array)
x_out = np.max(P) #In this case, could also have been other outliers
x_mean = np.mean(P)
x_std = np.std(P,ddof=1)
#Use the Erf function
Q = norm.cdf(x_out,x_mean,x_std)
#You could have also defined the Erf on your own
#Check if it is a high 'outlier'
if Q > 0.5:
Q = (1-Q)
#Use Chauvenets criterion
C = 2 * len(P) * Q
if C < 0.5:
print('The value can be discarded.')
else:
print('The value cannot be discarded.')
7.5.5. Standaard onzekerheid en significante cijfers#
Een belangrijke regel met betrekking tot significantie is dat je eerst het aantal decimalen van je onzekerheid bepaalt. Als je minder dan \(10^3\) meetpunten hebt, heeft de onzekerheid één significant cijfer. Je past hier de significantie van je resultaat hier op aan, zodat het laatste cijfer dezelfde waarde heeft als je onzekerheid. Je kunt gebruik maken van machten van 10 of voorvoegsel om het getal duidelijk weer te geven, zie tabel hieronder.
Voorbeeld:
Vraag: Bepaal de gemiddelde waarde (inclusief onzekerheid) van de volgende meetserie.
Meting |
\(U\) (V) |
|---|---|
1 |
5.050 |
2 |
4.980 |
3 |
5.000 |
4 |
4.950 |
5 |
5.020 |
Eerst bepalen we de gemiddelde waarde \(\mu(U)=\overline{U}=\frac{1}{N}\sum_{i=1}^{N} U_i = 5.000\) V.
Dan bepalen we de standaard deviatie \(\sigma(U) = \sqrt{\frac{1}{N-1}\sum_{i=1}^N (U_i-\overline{U})^2} = 0.038078866\) V.
Als laatste bepalen we de onzekerheid in de gemiddelde waarde \(u(U) = \frac{\sigma(U)}{\sqrt{N}} = 0.017029386\) V.
We hebben minder dan \(10^3\) meetpunten, dus de onzekerheid ronden we af op 1 decimaal: \(u(U) = 0.02\) V.
De onzekerheid heeft twee decimalen, dus hier passen we ons gemiddelde op aan: \(\overline{U} = 5.00 \pm 0.02\) V.
Er is nog wel een belangrijk punt aangaande afronden. Als je alle vijven naar boven af zou ronden, zou je een systematische fout introduceren, je rondt altijd af naar boven. De afspraak is dat bij een even getal voor de 5 naar beneden wordt afgerond (33.45 \(\rightarrow\) 33.4), bij een oneven getal voor de 5 wordt naar boven afgerond (33.55 \(\rightarrow\) 33.6). Daarnaast is het in sommige vakgebieden goed gebruik dat de onzekerheid niet afgerond wordt naar beneden, dit voorkomt een onderschatting van de onzekerheid. Binnen het natuurkundig practicum letten we daar echter niet op.
Tabel: Machten van 10 met bijbehorend symbool.
macht van 10 |
\(10^{-12}\) |
\(10^{-9}\) |
\(10^{-6}\) |
\(10^{-3}\) |
\(10^{-2}\) |
\(10^{-1}\) |
\(10^1\) |
\(10^2\) |
\(10^3\) |
\(10^6\) |
\(10^9\) |
\(10^{12}\) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
voorvoegsel |
pico |
nano |
micro |
milli |
centi |
deci |
deca |
hecto |
kilo |
mega |
giga |
tera |
symbool |
p |
n |
\(\mu\) |
m |
c |
d |
da |
h |
k |
M |
G |
T |
Voor extra informatie over significante cijfer kan je dit filmpje bekijken.
7.6. Doorwerken van onzekerheden#
Vaak laat je een berekening op je ruwe data los om tot een antwoord op je onderzoeksvraag te komen. Een kleine afwijking in je meting kan grote gevolgen hebben voor je eindantwoord. Daarom is het belangrijk om rekening te houden met het doorwerken van onzekerheden. Er zijn twee methodes om fouten door te rekenen; de functional approach en de calculus approach. De eerstgenoemde is wat intuïtiever, maar de tweede is dan weer iets makkelijker uit te rekenen.
We gaan er in de onderstaande theorie vanuit dat we een functie \(Z\) toepassen op onze empirisch bepaalde waarde \(x\) waarvan het gemiddelde \(\overline{x}\) is met een onzekerheid \(u(x)\).
7.6.1. Functional approach#
Bij de functional approach kijk je naar het verschil als je de functie evalueert in het punt dat één onzekerheid van je meetpunt af ligt. In formulevorm wordt het dan:
In veel gevallen is er sprake van symmetrie waardoor bovenstaande vergelijking ook opgevat kan worden als:
Voorbeeld:
Vraag: Bereken de omtrek van een cirkel met straal
\(r = 2 \pm 0.1 \) cm
Antwoord: \(O = 2\pi r = 4.0\pi \approx 12.5664 \) cm
\(u(O) = \frac{O(2+0.1) - O(2-0.1)}{2} = 2\pi\frac{2.1-1.9}{2} \approx 0.628..\)cm
\(O = 12.6 \pm 0.6\)cm
De functional approach is heel handig toe te passen bij berekeningen die je moet herhalen. Je definieert in python eerst de functie en laat vervolgens voor de variabelen + onzekerheid de uitkomst uitrekenen, zie de code hieronder voor het gegeven voorbeeld. Dit scheelt je een hoop tijd en rekenwerk. Echter, bij het opzetten van een nieuwe methode geeft de calculus approach een beter beeld van de grootte van de onzekerheden. Met behulp van de calculus approach kun je je experiment dimensioneren.
import numpy as np
def omtrek(x,a):
return 2*np.pi*(x+a)
r = 2.0
ur = 0.1
u_omtrek = (omtrek(r,ur)-omtrek(r,-ur))/2
print(u_omtrek)
0.6283185307179586
7.6.2. Calculus approach#
Bij de calculus methode gebruik je partiële afgeleides om het effect van een fout te lineariseren:
Een gevolg van het lineair benaderen van de fout is dat deze methode minder nauwkeurig wordt naarmate de fout groter wordt of de functie sterk niet-linear gedrag vertoont.
Voorbeeld:
Vraag: Bepaal de vergelijking voor de onzekerheid in \(f(x) = 2x\cos{x}\)?
Antwoord: We gebruiken de calculus approach. Hiertoe bepalen we de afgeleide van \(f(x)\) naar \(x\).
Vervolgens passen we de calculus approach toe:
7.6.3. Meerdere variabelen#
Als je resultaat een functie van meerdere onafhankelijke variabelen is, tel je de fouten kwadratisch op:
Met de calculus methode is af te leiden dat de onzekerheid \(u(f)\) voor een functie \(f(y,x)=cy^nx^m\) geldt:
Exercise 7.5
Eric weegt een doos. De massa is (56 \(\pm\) 2) g. De doos heeft zijden van (3.0 \(\pm\) 0.1) cm.
Bereken de zwaartekracht op de doos.
Bereken het volume van de doos.
Bereken de dichtheid van de doos.
Solution to Exercise 7.5
\((0.55 \pm 0.02) \) N
\((27 \pm 3)\) cm\(^3\)
\((2.1 \pm 0.2) \) g/cm\(^3\)
Voorbeeld:
Vraag: Bereken de onzekerheid in \(g(x,y) = \ln(x)e^{2y}\)
Antwoord: We gebruiken de calculus approach. Hiertoe bepalen we de partiële afgeleides van \(g(x)\) naar \(x\) en \(y\).
Vervolgens tellen we de onzekerheden kwadratisch op:
Tip
Standaard functies Tabel: Overzicht van veelgebruikte functies en bijbehorende onzekerheden.
Functie \(Z(x,y)\)
\(\frac{dZ}{dx}\)
Onzekerheid \(u(Z)\)
\(x + y\)
1
\(\sqrt{u(x)^2+u(y)^2}\)
\(x \cdot y\)
y
\(\sqrt{(y\cdot u(x))^2+(x\cdot u(y))^2}\)
\(x^n\)
\(n\cdot x^{n-1}\)
\(\vert n\cdot x^{n-1}\cdot u(x)\vert\) or \(\vert\frac{u(Z)}{Z}\vert = \vert n\frac{u(x)}{x}\vert\)
\(e^{cx}\)
\(ce^{cx}\)
\(ce^x \cdot(cx)\) or \(Z \cdot u(x)\)
\(n^x\)
\(n^x \ln{n}\)
\(n^x \ln{n} \cdot u(x)\)
\(\ln{x}\)
\(\frac{1}{x}\)
\(\frac{u(x)}{x}\)
\(\sin{x}\)
\(\cos{x}\)
\(\vert\cos{x}\vert\cdot u(x)\)
\(\cos{x}\)
\(-\sin{x}\)
\(\vert\sin{x}\vert\cdot u(x)\)
\(\tan{x}\)
\(1+\tan^2{x}\)
\((1+\tan^2{x})\cdot u(x)\) or \((1+Z^2) \cdot u(x)\)
Tip
Rekenregels
Reminder:
Functie
Afgeleide
\(f(x)\cdot g(x)\)
\(f'(x)g(x) + f(x)g'(x)\)
\(\frac{f(x)}{g(x)}\)
\(\frac{g(x)f'(x)-f(x)g'(x)}{g'(x)^2}\)
\(f(g(x))\)
\(f'(g(x))g'(x)\)
Let op, heb je twee waardes A en B die dicht bij elkaar liggen en trek je die van elkaar af (A-B), dan kan het zomaar zo zijn dat je fout veel groter is dan de het verschil tussen die twee waarden. In zulke gevallen moet je dan op zoek naar alternatieve meetmethodes die een kleinere relatieve onzekerheid opleveren. Zie hieronder een voorbeeld ter inspiratie.
Voorbeeld: verkleinen meetonzekerheid:
Voor een experiment willen we het frequentieverschil \(\Delta f\) van twee >tonen \(f_0\) en \(f_1\) bepalen. Na een meting blijkt \(f_0 = (1250 \pm 3)\) Hz en \(f_1 = (1248 \pm 4)\) Hz. Het verschil (inclusief onzekerheid) komt daarmee op \(\Delta f = (2 \pm 5)\) Hz (ga na).
Bij het aftrekken van waarden die dichtbij elkaar liggen, is de kans aanwezig dat de onzekerheid groter is dan de bepaalde waarde zelf. We kunnen dan ook nauwelijks goede conclusies trekken. In zulke situaties is het nodig na te denken over alternatieve manieren om hetzelfde te meten. In dit geval kan dit bijvoorbeeld door gebruik te maken van het natuurkundig fenomeen van zweving. Door de wevingsperiode te bepalen kun je eenvoudig het frequentieverschil bepalen.
Fig. 7.17 Tijdsafhankelijke meting van afzonderlijke signalen.#
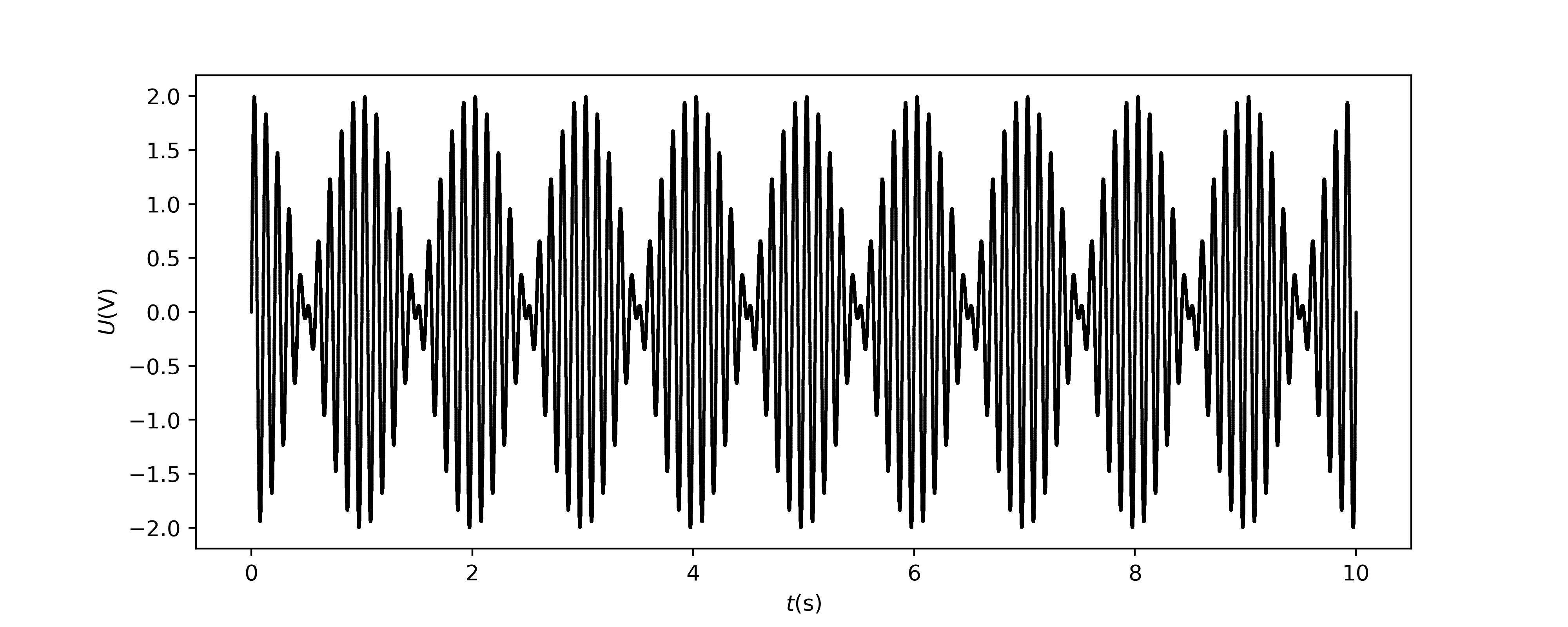
Fig. 7.18 Een alternatieve methode om het frequentieverschil van twee signalen te bepalen. Som van beide signalen. Het frequentieverschil is twee keer de frequentie van het omhulsel van de som.
Exercise 7.6
De tabel hieronder weergeeft metingen van het voltage over en de stroom door een lamp.
Tabel: Meting aan een lamp.
\(U\)(V) |
\(u(U)\)(V) |
\(I\)(mA) |
\(u(I)\)(mA) |
|---|---|---|---|
6.0 |
0.2 |
0.25 |
0.1 |
1. Bepaal het vermogen dat de lamp opneemt.
2. Bepaal de weerstand van de lamp.
3. Als je het voltage òf de stroom nauwkeuriger zou kunnen meten, welke zou je dan kiezen en waarom?
Exercise 7.7
In de tabel hieronder zijn de waarden en onzekerheden voor variabelen \(A\), \(B\), en \(C\) gegeven. Bereken de waarde en onzekerheden van \(Z\) voor de onderstaande gevallen.
Tabel: Drie variabelen en hun onzekerheden.
\(A\) |
\(u(A)\) |
\(B\) |
\(u(B)\) |
\(C\) |
\(u(C)\) |
|---|---|---|---|---|---|
5.0 |
0.1 |
500 |
2 |
1 |
0.1 |
\(Z = \frac{A}{BC^2}\)
\(Z = \frac{A}{BC^4}\)
\(Z = C\sqrt{AB}\)
7.6.4. Dimensioneren#
Een voordeel van de Calculus methode boven de Functional Approach is dat je je experiment kunt dimensioneren: Op basis van voorafgestelde criteria kun je aangeven hoe groot het experiment moet zijn, welke eigenschappen het moet hebben en waar de meeste tijd en aandacht in gestopt moet worden zodat het voldoet aan de gestelde criteria. Het makkelijkst is dit weer uit te leggen aan de hand van een voorbeeld.
Voorbeeld:
Je wilt met behulp van een massa-veer systeem nauwkeurig de massa van 10 verschillende gewichtjes bepalen. De fabrikant stelt dat de gewichtjes een massa hebben van (50 ± 3) g. Je wilt echter per gewichtje exactere de weten, op gram nauwkeurig. De maximale relatieve onzekerheid is dus 2%. Hoe ziet het experiment er uit?
De massa van het massa veersysteem volgt uit:
De onzekerheid in de massa wordt daarmee gegeven door:
De massa is hier de massa van het gewichtje aan de veer \(m_w\) en een onbekend deel van de massa van de veer \(m_C\) zelf:
De onzekerheid in de massa van het gewichtje wordt daarmee:
Op basis van deze vergelijking en de eis dat \(u(M_w)^2 < 1\)g en de wetenschap dat \(m\approx50\)g kan het experiment verder gedimensioneerd worden. Aangezien de veerconstante \(C\) en de bijdrage van de massa van de veer \(m_C\) vooraf bepaald kunnen worden, volgt het aantal te bepalen periodes uit deze vergelijking. Deze kennis wordt met name toegepast in het open onderzoek aan het eind van dit vak en bij het vak Design Engineering voor Fysici (DEF) in het volgende semester. Waar je bij het practicumvak werkt naar de uitvoering van het experiment, zou je bij DEF eisen stellen aan de veer: hoe nauwkeurig moet de veer gemaakt worden (d.w.z., wat is de tolerantie die je van de maker van de veer eist).
7.7. Functiefit#
Vaak meten we een grootheid als functie van een andere grootheid, bijvoorbeeld de rek van een veer als functie van de veerbelasting of de slingertijd als functie van de lengte van de slinger. Het doel daarvan kan verschillend zijn. We kunnen ons bijvoorbeeld afvragen: hoe (volgens welk functioneel verband) hangt de rek af van de belasting? Of: wat is de veerconstante van de veer? We veronderstellen dan een bepaald verband en gebruiken dat verband om de waardes van parameters vast te stellen. In het eerste geval spreken we van modelleren, in het tweede geval van aanpassen of “fitten”. In de statistiek staat het tweede geval bekend als een regressieprobleem. Hier zullen we nader op ingaan.
Fitten is een procedure waar wordt geprobeerd om een mathematisch verband te vinden in een aantal (meet)punten. We zijn dan op zoek naar een verband \(F(x)\) die de meetpunten \(M(x)\) beschrijft, zodanig dat:
Eerst is het nodig om een type verband te kiezen. Voorbeelden zijn een lineaire fit, een polynoom, sinus, etc. In de fitprocedure zelf worden de parameters van dit verband zo gekozen, dat ze het beste overeenkomen met de data. Als een 2\(\textrm{e}\) orde polynoom wordt gefit bijvoorbeeld, zoek je welke combinatie van \(a\), \(b\), en \(c\) ervoor zorgen dat de curve \(a + bx + cx^2\) zo goed mogelijk op je meetpunten ligt.
Een veelgebruikte methode om de goedheid van een fit te bepalen is de least-squares methode. Hierin wordt de som van de gekwadrateerde afstand van de meetpunten tot de fit geminimaliseerd. Daartoe definiëren we eerst de afstand tussen de meetpunt en de fit:
Deze afstand wordt ook wel het residu genoemd, hier gaan we later ook dieper op in. De totale som van de absolute afstanden moet zo klein mogelijk worden:
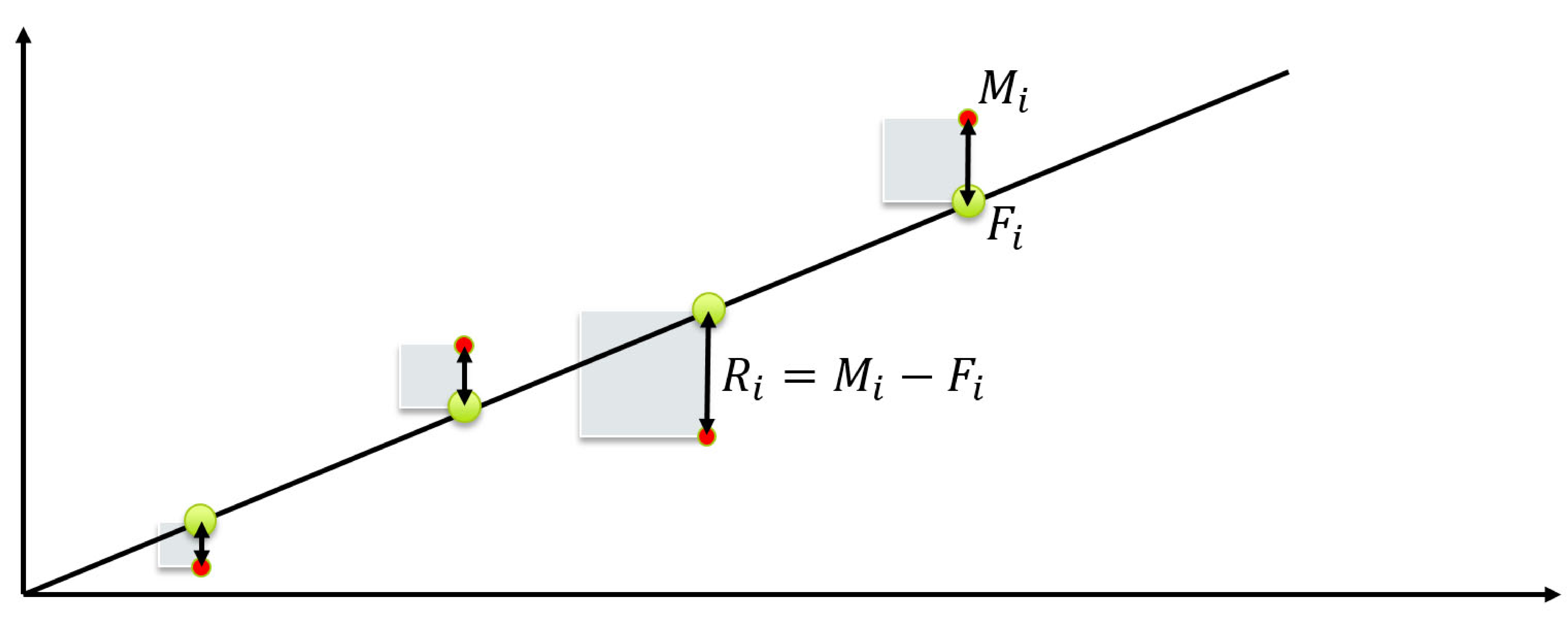
Fig. 7.19 Het idee van een least-square methode is dat het oppervlak zo klein mogelijk gemaakt wordt#
Je kunt hieronder door te spelen met de sliders kijken wanneer \(\chi^2\) zo klein mogelijk is.
In bovenstaande geval gaan we uit dat de waarde van de onafhankelijke variabele voldoende nauwkeurig en precies is bepaald. Er zijn andere technieken die rekening houden met de afwijking in de afhankelijke variabele. Ook kunnen we wederom kijken naar de invloed van meetonzekerheid in het bepalen van de beste fit.
7.7.1. Gewogen fit#
Net als dat bij een gewogen gemiddelde rekening gehouden wordt met de onzekerheid in de meting, kun je bij een functiefit gebruik maken van een gewogen fit. Je houdt dan rekening met de onzekerheid in de afhankelijke variabele (er is ook een techniek die rekening houdt met zowel de onzekerheid in de onafhankelijke als afhankelijke variabele, die behandelen we hier niet).
Voor een gewogen fit wordt er gekeken naar de kleinste waarde voor \(\chi^2\) waarbij de onzekerheid meegewogen wordt:
7.7.2. Andere fit#
Bij een least-square fit proberen we het residu (in het kwadraat) zo klein mogelijk te maken. Dat gaat vooral goed onder de aanname dat de onzekerheid in de afhankelijke variabele zit. We zijn dus in staat om de onafhankelijke variabele zelf in te stellen, of de onzekerheid zo ver te reduceren dat deze verwaarloosd kan worden t.o.v. de onzekerheid in de afhankelijke variabele. Maar de least-square methode is niet de enige methode. Er is bijvoorbeeld ook de ‘orthogonal distance regression’ ofwel, kleinste afstand methode. De methode is gevisualiseerd in Figuur {number}. De verdere wiskundige uitwerking zullen we hier niet geven, maar hoe de methode geïmplementeerd kan worden, is te vinden in deze bron.
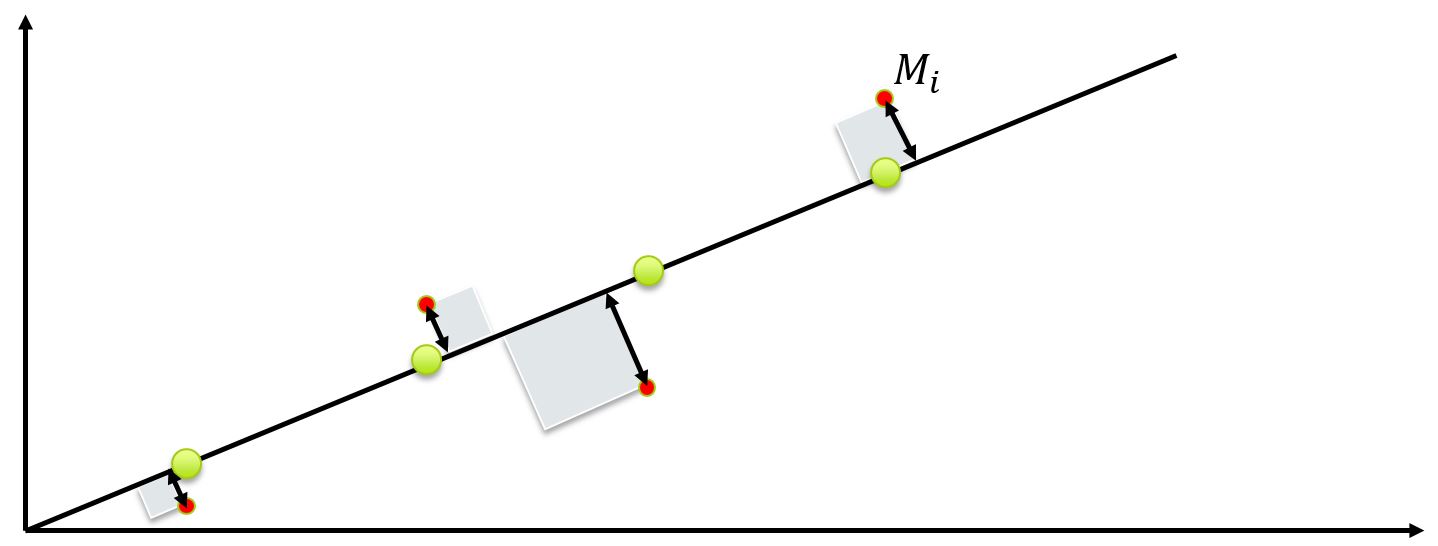
Fig. 7.20 Een andere fit methode is de ODR die de afstand tot de fitlijn zo klein mogelijk maakt#
7.8. Analyse van het residu#
In een van de eerdere secties is gesproken dat een fysische meting (\(M(x)\)) beschreven kan worden als de optelsom van de fysische waarde (\(G(x)\)) + ruis (\(s\)). Een functiefit (\(F(x)\)) gebeurt op basis van de metingen. Om te controleren dat we een goede fit te pakken hebben, moeten we nog naar de ruis kijken. Deze zouden we krijgen wanneer we de fitfunctie aftrekken van de meting:
De eerste analyse gebeurt door de ruis \(s\) als functie van de onafhankelijke grootheid \(x\) te plotten. Als daar een patroon in zit, bijvoorbeeld stijgende lijn, een sinus-vormig signaal, of alle ruispunten boven de 0, zie Figuur {number}, dan is er grote kans dat er een betere functie \(F(x)\) te vinden is die de fysische waarde \(G(x)\) beschrijft.
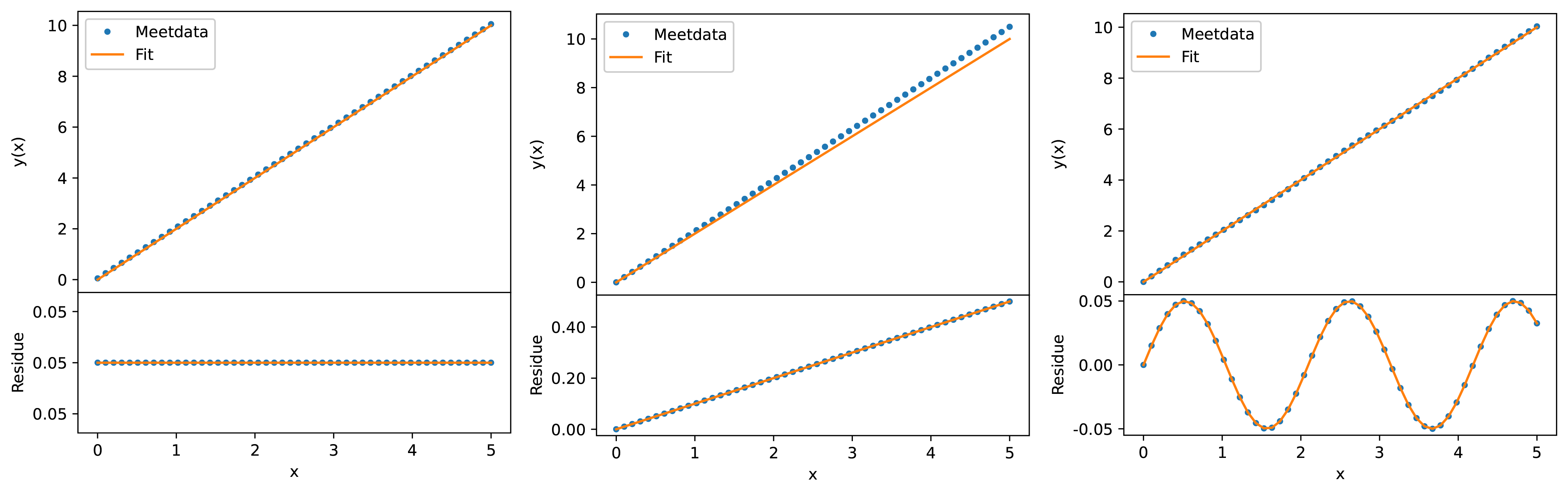
Fig. 7.21 (a) \(M(x) = 2x + 0.05 \), (b) \(M(x) = 2x + 0.1x\) en \((c) M(x) = 2x + 0.05sin(3x)\). In elk van de metingen zit een ‘verborgen’ singaal dat zichtbaar wordt bij analyse van de residuals. Voor alle figuren is er een lijn \(F(x) = 2x\) gefit.#
De tweede analyse van het residu is op basis van een histogram. Als je op basis van het experiment verwacht dat de ruis normaal verdeeld is, dan zal het histogram een normaal verdeelde functie zijn. Ook over dit ruis signaal kun je een functiefit leggen, waarbij we verwachten dat het gemiddelde 0 is, en de standaard deviatie bepaald kan worden.
7.8.1. Linearisatie#
Tijdens het experimenteren is het doel vaak om de relatie tussen twee variabelen te ontdekken. In veel gevallen is deze relatie niet lineair, bijvoorbeeld tussen de slingertijd en lengte van een slinger. In zulke gevallen is het inzichtelijk om de grafieken te lineariseren. Ten eerste is het makkelijker om zo afwijkingen te zien, en ten tweede is het fitten ook eenvoudiger.
Voorbeeld:
Voorbeeld: We willen de waarde van de valversnelling \(g\) bepalen. Hiertoe doen we metingen tussen de slingertijd \(T\) en de lengte \(L\) van een slinger.
Volgens de theorie is het verband tussen de slingertijd en lengte als volgt: \(T = 2\pi\sqrt{\frac{L}{g}}\) Als we beide kanten van de vergelijking kwadrateren, krijgen we: \(T^2 = 4\pi^2 \frac{L}{g}.\) Door \(T^2\) op de y-as te plotten als functie van \(L\), hebben de functie gelinealiseerd, en kunnen we systematische fouten beter detecteren.
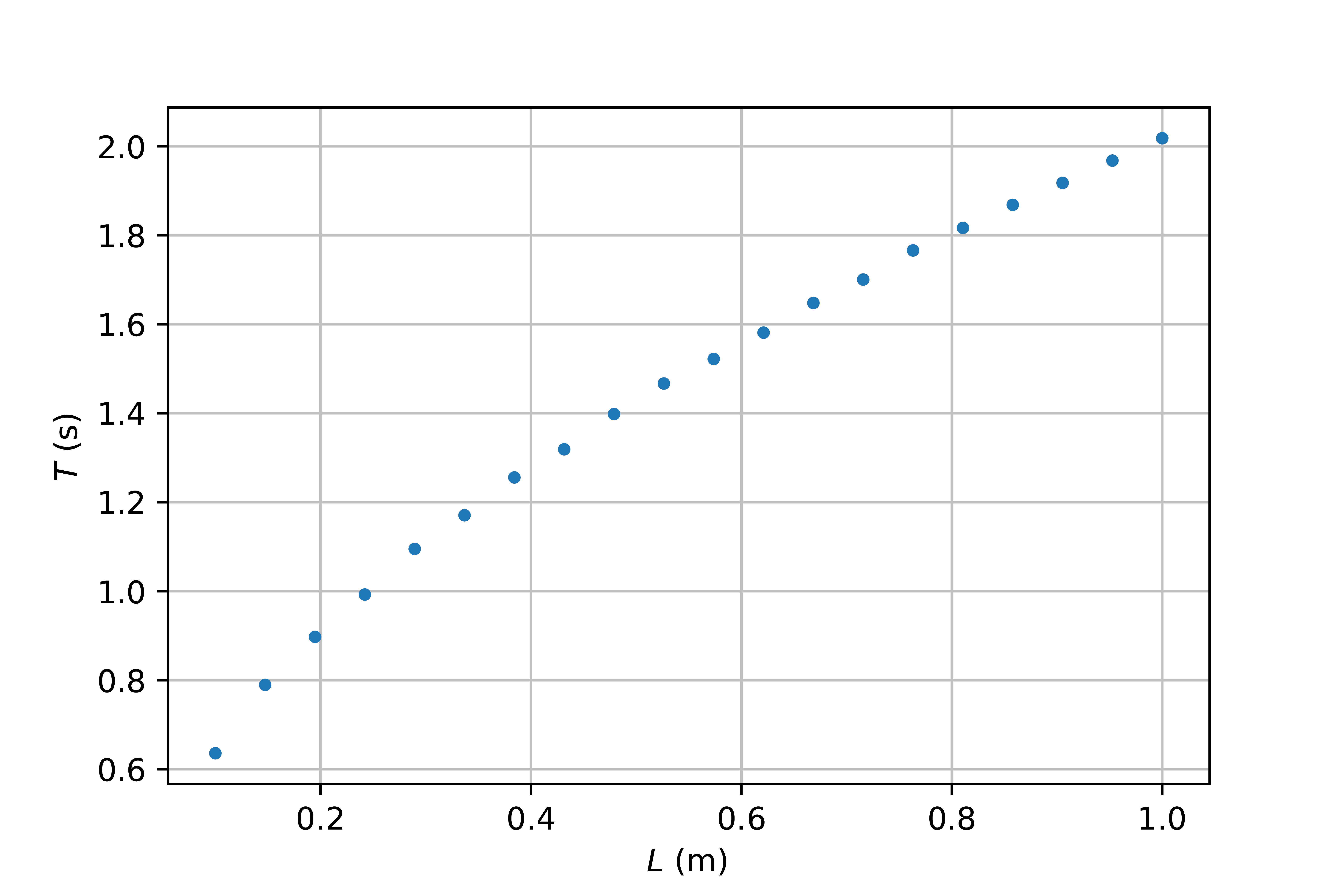
Fig. 7.22 Metingen van de slingertijd als functie van de slingerlengte. Ruwe data geplot, er is een wortelverband zichtbaar.#
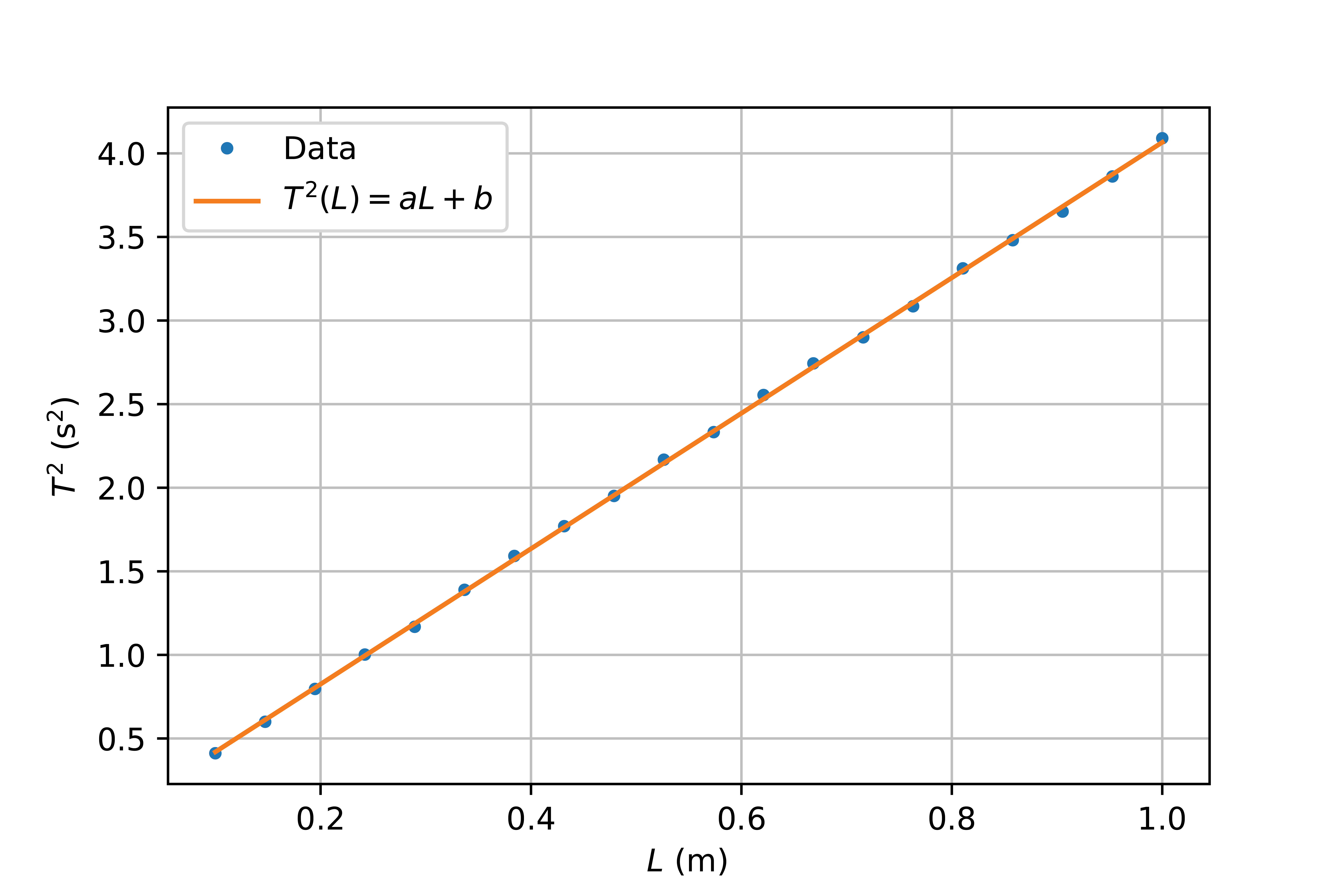
Fig. 7.23 Gelineariseerde data uit Figuur {number} door \(T^2\) uit te zetten tegen \(L\). Een eerste order polynoom \(T^2(L)=aL + b\) is gefit met coëfficiënten \(a = (4.05 \pm0.01)\) s\(^2\)/m en \(b = (0.015 \pm 0.09)\) s\(^2\)#
7.8.2. Strijdigheidsanalyse#
Een van de belangrijkste redenen om de onzekerheid te bepalen is dat je resultaten onderling of met theoretische voorspellingen systematisch en kwantitatief wilt vergelijken en zo na wilt gaan in hoeverre de waarden van elkaar verschillen. De vraag is dan: ‘In hoeverre komen de empirisch gevonden waarden overeen met …’.
Stel dat we twee waarden \(a\) en \(b\) elk met hun eigen onzekerheid \(u(a)\) en \(u(b)\) willen vergelijken. Dan willen we eerst kijken naar het verschil tussen deze twee waarden: \(v = a- b\). Op basis van de calculus approach wordt de onzekerheid in \(v\) gegeven door \(u(v) = \sqrt{u(a)^2 + u(b)^2}\). De afspraak is nu dat twee waarden strijdig met elkaar zijn (in wetenschappelijke zin onvoldoende met elkaar overeenkomen) als geldt:
Voor de bepaling van natuurkundige constanten, is de onzekerheid vaak zo klein dat deze ten opzichte van de andere onzekerheid te verwaarlozen is. Let op! Je kunt beargumenteren dat als je meetonzekerheid maar groot genoeg is, de waarden nooit strijdig zullen zijn. Maar wanneer de onzekerheid relatief groot is ten opzichte van de bepaalde waarde, dan heeft de gevonden waarden ook weinig wetenschappelijke waarde.
7.9. Goede voorbeelden van slechte grafieken#
Er zijn heel veel manieren waarop je je data slecht kunt presenteren. Er zijn maar een paar manieren waarop dat goed kan. Belangrijkste bij het maken van een grafiek is dat deze overzichtelijk is, dat helder is voor de lezer waar er naar gekeken moet worden.
Figuur {number} is een goed voorbeeld van een slechte grafiek. Allereerst is de trend niet te zien. Er is een punt dat ruim boven de andere liggen, maar zijn de waarden voor \(r>11\) gelijk aan 0 of niet? Daarnaast staan er veel te veel getallen (ticks) op de horizontale as. Ook is de indeling van de schaal voor de horizontale as slecht gekozen. We missen verder nog wat er eigenlijk op de horizontale as en verticale as is gepresenteerd.
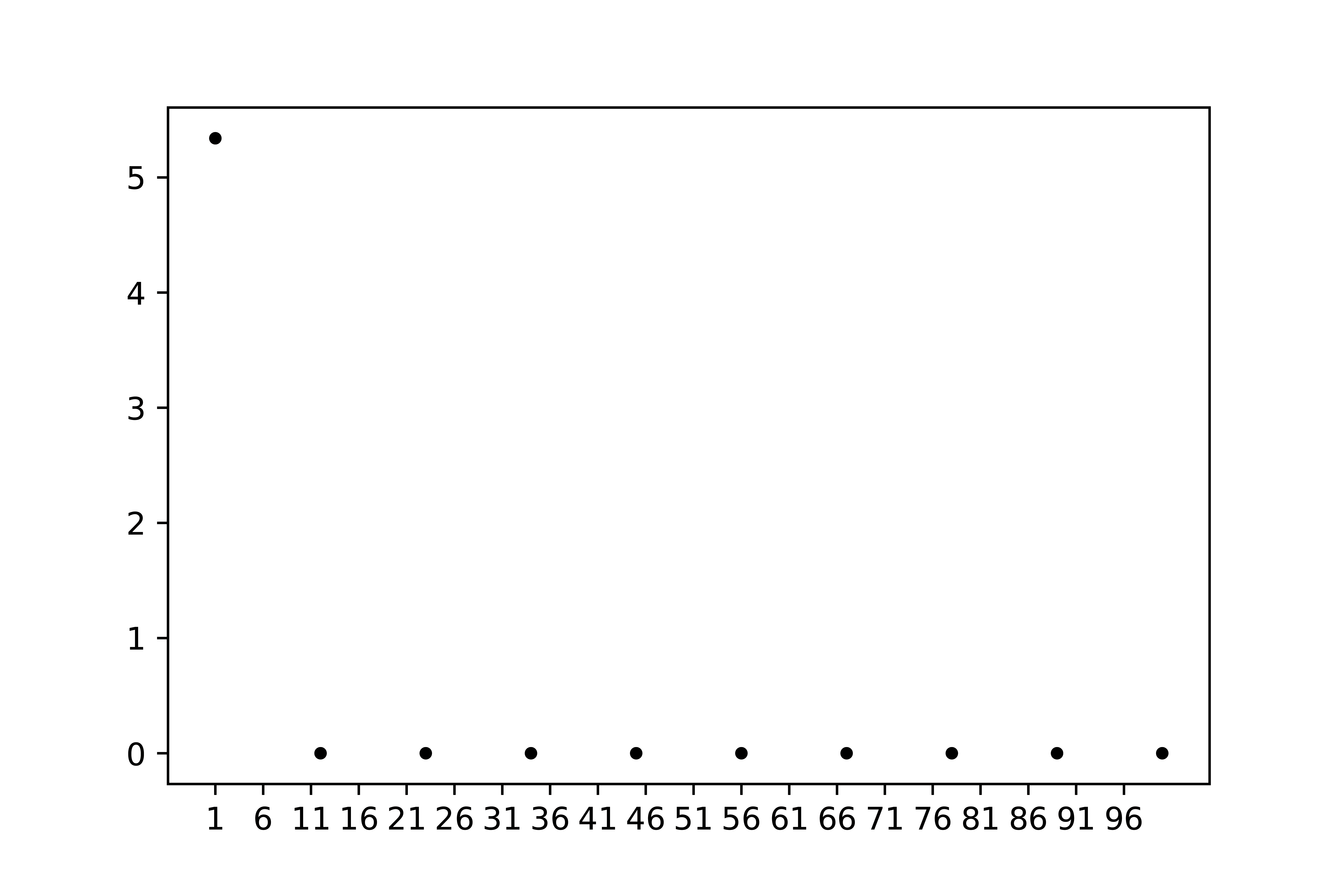
Fig. 7.24 Een goed voorbeeld van een slechte grafiek#
Figuur {number} presenteert dezelfde data. De verschillen mogen duidelijk zijn, de data zijn weergegeven op een log-log schaal, een trendlijn laat zien wat de relatie is tussen de kracht en de afstand. Het aantal ticks is beperkt. De grafiek zou nog verder verbeterd kunnen worden door de meetonzekerheid mee te geven.
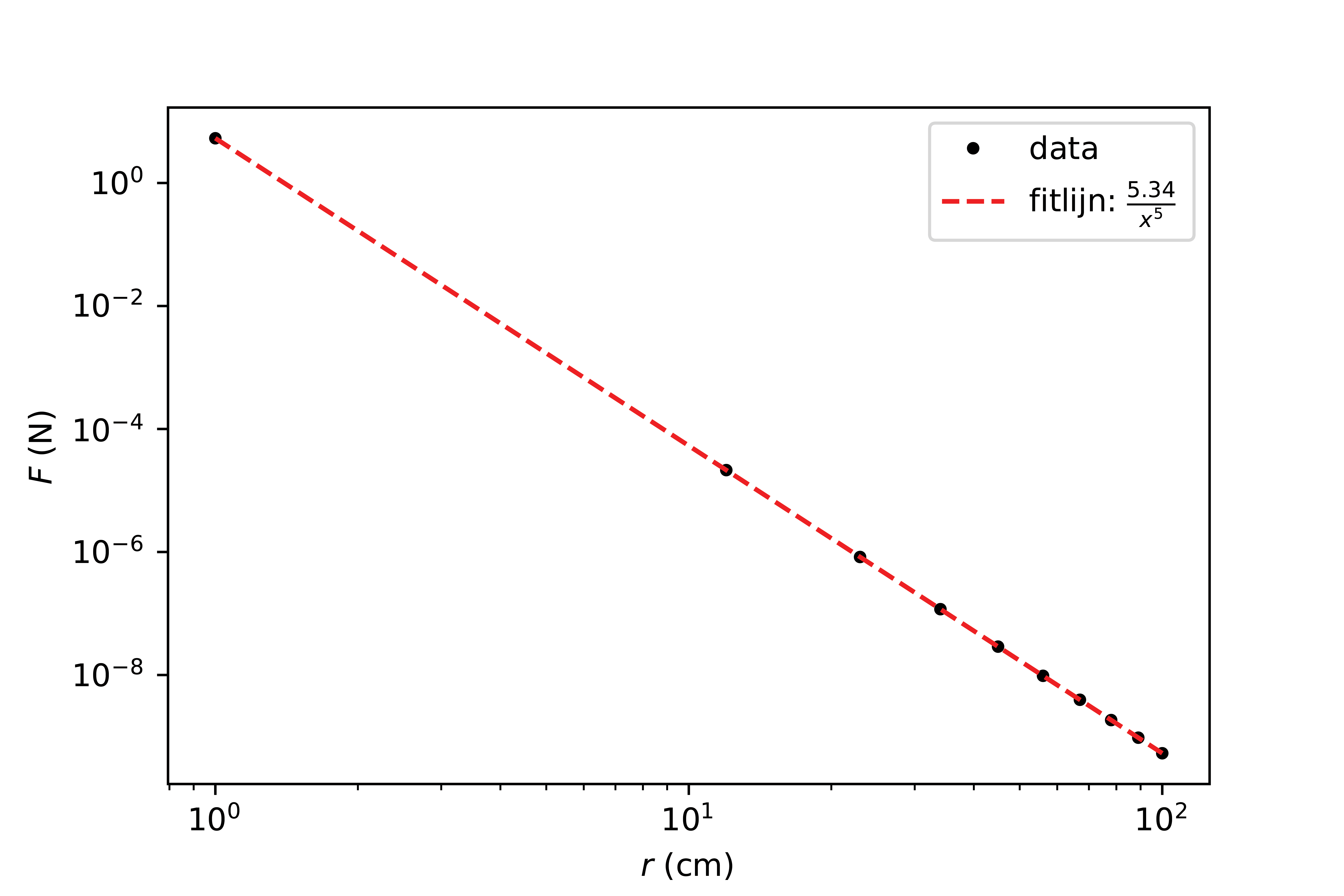
Fig. 7.25 Een verbeterde versie van de grafiek#
7.10. Verder lezen#
Enkele bronnen die gaan over het gebruik van data en meetonzekerheid:
Guide to the expression of uncertainty in measurement
Liegen met cijfers
Het bestverkochte boek ooit
7.11. Oefeningen#
Exercise 7.8
In de tabel hieronder zijn de waardes van \(a\) en \(x\) gegeven.
a
\(u(a)\)
x
\(u(x)\)
\(5\cdot10^{-8}\)
\(1\cdot10^{-9}\)
\(5\cdot10^{-3}\)
\(1\cdot10^{-3}\)
Bepaal de waarde en onzekerheid van \(F = a \cdot x^{-4}\).
Doe hetzelfde als in de vorige opgave, maar neem nu \(u(a) = 1 \cdot 10^{-9}\) en \(u(x) = 1 \cdot 10^{-10}\). Wat valt je op?
Houd nu \(u(a)\) constant, en neem \(u(x) = 1\cdot 10^{-3}\) en \(u(x) = 1\cdot 10^{4}\). Wat valt je op?
Vergelijk je antwoorden bij vraag b) en c). Waarom schaalt de fout in \(F\) lineair met de fout in \(a\) maar niet met \(x\)?
Exercise 7.9
Leid vergelijking () af.
Exercise 7.10
Beschouw een balk met lengte \(L=(7.5\pm0.1)\) m, breedte \(B=(12.5\pm0.2)\) cm en hoogte \(H=(15.0\pm0.3)\) cm. Het oppervlakte \(A\) wordt gegeven door \(B \cdot H\). Bepaal de onnauwkeurigheden \(u(A)\) en \(u(V)\).
Exercise 7.11
Met behulp van een pendulum wordt de valversnelling \(g\) bepaald. De slingertijd is \(T = (1.60\pm0.03)\) s en de lengte van de slinger is \(L = (64.0\pm0.8)\) cm.
Geef het verband tussen de slingertijd en de slingerlengte.
Leid uit dit verband een formule af voor de valversnelling \(g\).
Geef de onnauwkeurigheidsformule voor \(u(g)\).
Bereken \(g\) en \(u(g)\) en noteer de resultaten op de juiste wijze.
Welke variabele heeft de grootste invloed op de onnauwkeurigheid?
Exercise 7.12
De relatie tussen grootheid \(G\) hangt af van de gemeten grootheden \(x\) en \(y\) wordt gegeven door \(G(x,y)=\frac{1}{2} x y^{3} + 5 x^{2} y\). De onnauwkeurigheden in \(x\) en \(y\) zijn respectievelijk \(u(x)\) en \(u(y)\). Bepaal de onnauwkeurigheidsformule voor \(u(G)\).
Exercise 7.13
Beschouw een bol met straal \(R=(3.02 \pm 0.06)\) m. Bepaal het oppervlak \(A\) en het volume \(V\) met bijbehorende (relatieve) onnauwkeurigheden.
Exercise 7.14
Beschouw \(f(x)=2\sin{x}\), waarbij \(x\) een gemeten grootheid is met onnauwkeurigheid \(u(x)\). Leid een formule af voor de onnauwkeurigheid \(u(f)\).
Exercise 7.15
Hoe kan je de onderstaande relaties (1-4) lineariseren, zodat je ze als rechte lijn \(y = mx + c\) kunt plotten? Geef de uitdrukking voor de helling \(m\), en het snijpunt \(c\).
\(V = aU^2\)
\(V = a\sqrt{U}\)
\(V = a \exp{(-bU)}\)
\(\frac{1}{U} + \frac{1}{V} = \frac{1}{a}\)